|
Intel is set to commence the next salvo in the server CPU core wars, with plans to launch two new generations of Xeon processors in 2020. Much like its mainstream mobile plans, Intel will have a 10nm and 14nm solution. But where those chips stick to four cores at most, Intel’s new server CPUs are looking to chase down AMD’s Epyc 64-core chips, with 38 and 48-core options of its own. When AMD introduced its first-generation Epyc server CPUs with up to 32 cores and 64 threads in 2017, it pushed the boundary of what was possible for a single socket chip. It did so again in 2019 with the launch of Epyc Rome chips based on the new Zen 2 architecture with up to 64 cores and 128 threads. It also broke new ground on PCIe lanes, offering up to 128 per chip with each generation. Although Intel’s server performance was roughly comparable in a number of ways, by the numbers at least, it’s been playing catchup. 
Until early 2019, all Intel could offer was 28 cores and 56 threads. Some special, soldered versions of Cascade Lake-AP offered up to 56, but they weren’t scalable outside of a single socket and second-generation Epyc was just months away from edging ahead again with 64. The next-generation(s) of Intel’s server chips aren’t set to break that record, with maximums of 38 cores for the Ice Lake chips, and 48 on the Cooper Lake option (as per WCCFTech), but they do increase the PCIe lanes to 64. Still half that of Epyc, but it’s a step in the right direction. Elsewhere, Intel appears to be aping features from AMD’s server chips more and more, too. Both new CPU generations are only scalable to two sockets, like Epyc. They also support eight-channel memory, just like Epyc does, as per HotHardware. They’re more power-hungry than their predecessors too, just like Epyc. But where the AMD CPUs max out at 225 watts, the new Intel Cooper Lake chips can draw as much as 300 watts from a single chip. These new releases will be good news for companies that have had Intel server chips for years and want to maintain that in the years to come. More cores, improved memory speed support, and a greater number of PCIe lanes are all welcome (Ice Lake-SP will even support PCIE 4.0), but it still feels like Intel is chasing AMD’s tail. Many of the features introduced with these new chips are less impressive than the recent AMD announcements, and they’re still not slated to debut until Q2 and Q3 in 2020. That’s when we’d expect to see a third-generation Epyc, codenamed Milan, to be making its debut. Scalability is one thing that Intel’s server line has had going for it in the face of Epyc’s rapid development and improvement, with Sky Lake and Cascade Lake systems offered in up to eight-socket variants. But the new Cooper Lake and Ice Lake chips are limited to just two sockets per system. That could alienate some unique use cases where Intel may have otherwise held an advantage. It’s also telling and frustrating that Intel is once again splitting its product lineup with two offerings in 14nm and 10nm. This is the same as we’ve seen with Comet Lake and Ice Lake on mobile. Both are releasing within months of each other, and both are labeled “10th-generation.” In that case and this one, Intel looks set to introduce an expansive, but confusing lineup of hardware, which we can’t help but question. This may be yet another example of Intel being unable to meet demand for Ice Lake, so it’s looking to spread it across an alternative new-generation of hardware. Whether that’s true or Intel just really wants to launch yet another 14nm CPU line, it could be too little too late. 64-core Epyc Milan server chips in 2020 won’t be far behind these, if not launch alongside the Ice Lake-SP option. If that happens, these chips will already look antiquated, as AMD moves to 7nm+ with TSMC’s EUV technology. Who wins in the end is up in the air, but the ramp up to higher and higher core counts sure is fun to keep up with. Editors' RecommendationsRead More Intel and AMD are in an all-out, core-count war - Digital Trends : https://ift.tt/2Pw0wr0
0 Comments
In a recent earning call, Intel CEO Bob Swan assured investors that the company’s much-waylaid production capacity for their 10nm fabrication is now sufficient to fully meet customer demand. Specifically, Swan indicated that their plants in Oregon and Israel are now producing 10nm Ice Lake chips at the levels needed to fill orders for both consumer- and data center-grade CPUs. Additionally, Intel’s Arizona facility should also be fully operational for 10nm production early next year. Anyone following Intel since at least as far back as this year’s Computex trade show knows that the industry giant has encountered more than a few issues in keeping up with AMD in terms of die shrinking. While Intel is only just now reliably putting out 10nm chips, AMD has already moved on to 7nm die sizes, although it too is hitting its share of production snags. 
In the immediate wake of Computex 2019, it seemed as though Intel was losing ground to its emboldened competitor. However, as more developments came to light, the picture gradually looked less and less bleak. For one thing, although its latest batch of chips are a tad bulkier than AMD’s, Intel proved its first wave of Ice Lake CPUs could measure up in performance. When pitted head-to-head, Intel’s Ice Lake i7-1065G7 running in an HP Spectre edged out AMD’s beefy Ryzen 9 3900X in single-core processing. And just when the prospects of 10nm desktop processors from Intel looked grim, with no word on the company for months following the initial announcement, Intel reassured consumers that a subsequent desktop wave is in the works. But Intel is doing more than just meeting AMD’s die size challenge head on. It is working tirelessly to outflank AMD by offering a broader strategy to improve the consumer computing experience. This makes a lot of sense considering that chip makers are having a harder time squeezing additional performance out of the CPU itself, and are instead turning to address smoother networking and dedicated processing units for specialized tasks like machine learning. To start with, Intel is doubling down on mobile performance with its forthcoming Lakefield series, which favors a hybrid embrace of large powerhouse cores paired with small lower-horsepower ones. 
Actually, one could say Intel is tripling down on mobile when considering its Project Athena. This initiative aims to power the next generation of 2-in-1 devices with hardware that more seamlessly pivots between mobile-optimized tasks. All of these ambitious pushes leave plenty for consumers to look out for in the months (and hopefully not years) ahead. Editors' RecommendationsRead More Intel’s long, painful struggle with 10nm production may finally be over - Digital Trends : https://ift.tt/34eg2vy
Intel likes 5.0 GHz processors. The one area where it claims a clear advantage over AMD is in its ability to drive the frequency of its popular 14nm process. Earlier this week, we reviewed the Core i9-9990XE, which is a rare auction only CPU but with 14 cores at 5.0 GHz, built for the high-end desktop and high frequency trading market. Today we are looking at its smaller sibling, the Core i9-9900KS, built in numbers for the consumer market: eight cores at 5.0 GHz. But you’ll have to be quick, as Intel isn’t keeping this one around forever. The Battle of the BitsEvery time a new processor comes to market, several questions get asked: how many cores, how fast, how much power? We’ve come through generations of promises of many GHz and many cores for little power, but right now we have an intense battle on our hands. The red team is taking advantage of a paradigm shift in computing with an advanced process node to offer many cores at a high power efficiency as well as at a good frequency. In the other corner is team blue, which has just equipped its arsenal by taking advantage of its most aggressive binning of 14nm yet, with the highest frequency processor for the consumer market, enabled across all eight cores and to hell with the power. Intel’s argument here is fairly simple: Do you want good all-around, or do you want the one with the fastest raw speed? The Intel Core i9-9900KS is borne from the battle. In essence it looks like an overclocked Core i9-9900K, however by that logic everything is an overclocked version of something else. In order for Intel to give a piece of silicon off the manufacturing like the name of a Core i9-9900KS rather than a Core i9-9900K requires additional binning and validation, to the extent where it has taken several months from announcement just for Intel to be happy that they have enough chips for demand that will meet the warranty standards.
At the time Intel launched its 9th Generation Core desktop processors, like the Core i9-9900K, I perhaps would not have expected them to launch something like the Core i9-9900KS. It’s a big step up in the binning, and I’d be surprised if Intel gets one chip per wafer that hits this designation. Intel announced the Core i9-9900KS after AMD had launched its Zen 2 Ryzen 3000 family, offering 12 cores with an all core turbo around 4.2 GHz and a +10% IPC advantage over Intel’s Skylake microarchitecture (and derivatives) for a lower price per core. In essence, Intel’s Core i9-9900K consumer flagship processor had a chip that was pretty close to it in performance with several more cores.
Intel is pushing the Core i9-9900KS as the ultimate consumer processor. With eight cores all running at 5.0 GHz, it is promising fast response and clock rates without any slowdown. Intel has many marketing arguments as to why the KS is the best processor on the market, especially when it comes to gaming: having a 5.0 GHz frequency keeps it top of the pile for gaming where frequency matters (low resolution), and many games don’t scale beyond four cores, let alone eight, and so the extra cores on the competition don’t really help here. It will be interesting to see where the 9900KS comes out in standard workload tests however, where cores can matter. The Intel Core i9-9900KS now sits atop of Intel’s consumer product portfolio. The processor is the same 8-core die as the 9900K, unlocked with UHD 620 integrated graphics, but has a turbo of 5.0 GHz. All cores can turbo to 5.0 GHz. The length of the turbo will be motherboard dependent, however.
The Core i9-9900KS has an tray price of $513 (when purchased in 1000 unit bulk), which means we’re likely to see an on-shelf price of $529-$549, depending on if it gets packaged in its hexagonal box that our review sample came in.
Compared to the Core i9-9900K or Core i9-9900KF, the Core i9-9900KS extends its 5.0 GHz all through from when 2 cores are active to 8 cores are active. There is still no Turbo Boost Max 3.0 here, which means that all cores are guaranteed to hit this 5.0 GHz number. The TDP is 127 W, which is the maximum power consumption of the processor at its base frequency, 4.0 GHz. Above 4.0 GHz Intel does not state what sort of power to expect. We have this testing further in the review. CompetitionAt present, Intel is competing against two major angles with the Core i9-9900KS. On the one side, it already has the Core i9-9900K, which if a user gets a good enough sample, can be overclocked to emulate the 9900KS. Intel does not offer warranty on an overclocked CPU, so there is something to be taken into account – the warranty on the Core i9-9900KS is only a limited 1 year warranty, rather than the standard 3 years it offers to the majority of its other parts, which perhaps indicates the lengths it went to for binning these processors. From AMD, the current 12-core Ryzen 9 3900X that is already in the market has become a popular processor for users going onto 7nm and PCIe 4.0. It offers more PCIe lanes from the CPU to take advantage of PCIe storage and such, and there are a wealth of motherboards on the market that can take advantage of this processor. It also has an MSRP around the same price, at $499, although is often being sold for much higher due to availability. AMD also has the 16-core Ryzen 9 3950X coming around the corner, promising slightly more performance than the 3900X, and aside from the $749 MSRP, it’s going to be an unknown on availability until it gets released in November.
It’s worth noting here that while Intel has committed to delivering ‘10nm class’ processors on the desktop in the future, it currently has made zero mention of exactly when this is going to happen. Offering a limited edition all-core 5.0 GHz part like the Core i9-9900KS into the market is a brave thing indeed – it will have to provide something similar or better when it gets around to producing 10nm processors for this market. We saw this once before, when Intel launched Devil’s Canyon: super binned parts that ultimately ended up being faster than those that followed on an optimized process, because the binning aspect ended up being a large factor. Intel either has extreme confidence in its 10nm process for the desktop family, or doesn’t know what to expect. This ReviewIn our review, we’re going to cover the usual benchmarking scenarios for a processor like this, as well as examine Intel’s relationship with turbo and how much a motherboard manufacturer can affect the performance. As per our processor testing policy, we take a premium category motherboard suitable for the socket, and equip the system with a suitable amount of memory running at the manufacturer's maximum supported frequency. This is also typically run at JEDEC subtimings where possible. It is noted that some users are not keen on this policy, stating that sometimes the maximum supported frequency is quite low, or faster memory is available at a similar price, or that the JEDEC speeds can be prohibitive for performance. While these comments make sense, ultimately very few users apply memory profiles (either XMP or other) as they require interaction with the BIOS, and most users will fall back on JEDEC supported speeds - this includes home users as well as industry who might want to shave off a cent or two from the cost or stay within the margins set by the manufacturer. Where possible, we will extend out testing to include faster memory modules either at the same time as the review or a later date.
Many thanks to...We must thank the following companies for kindly providing hardware for our multiple test beds. Some of this hardware is not in this test bed specifically, but is used in other testing.
How to Manage 5.0 GHz TurboIntel lists the Core i9-9900KS processor as having a 127W TDP. As we’ve discussed at length [1,2] regarding what TDP means, as well as interviewing Intel Fellows about it, this means that the Core i9-9900KS is rated to require a cooling power of 127W when running at its base frequency, 4.0 GHz. Above this frequency, for example at its turbo frequency of 5.0 GHz, we are likely to see higher than 127W. Now, I started saying in this review that the length of time that the processor will spend at 5.0 GHz will be motherboard dependent. This is true: Intel does not strictly define how long turbo should be enabled on any processor. It allows the motherboard manufacturer to ‘over-engineer’ the motherboard in order to help push the power behind the turbo higher and enable turbo for longer. The specific values that matter here are called PL2 (Power Limit 2, or peak turbo power limit), and Tau (a time for turbo). For an Intel processor, each one has a ‘bucket’ of extra turbo energy. As the processor draws more power above its TDP (also called PL1), the bucket is drained to provide this energy. When the bucket is empty, the processor has to come back down to the PL1 power value, and eventually when the processor is less active below PL1, the bucket will refill. How big this bucket is depends on the value of PL1, PL2, and Tau. The bigger the bucket, the longer an Intel processor can hold its turbo frequency. Typically Tau isn’t so much as a time for turbo, but a scalar based on how big that bucket should be.
Motherboard manufacturers can set PL1, PL2, and Tau as they wish – they have to engineer the motherboard in order to cope with high numbers, but it means that every motherboard can have different long turbo performance. Intel even suggests testing processors on high-end and low-end motherboards to see the difference. Users can also manually adjust PL1, PL2, and Tau, based on the cooling they are providing. For the Core i9-9900KS, Intel has given the PL1 value on the box, of 127 W. PL2 it says should at least be 1.25x the value of PL1, which is 159 W. Tau should be at least 28 seconds. This means, with a given workload (typically 95% equivalent of a power virus), the CPU should turbo up to 159 W for 28 seconds before coming back down to 127 W. A very important thing to note is that if the CPU needs more than 159 W to hit the 5.0 GHz turbo frequency, it will reduce the frequency until it hits 159 W. This might mean 4.8 GHz, or lower. Despite giving us these numbers for PL1, PL2, and Tau, Intel also stated to us that they recommend that motherboard manufacturers determine the best values based on the hardware capabilities. The values of 127 W, 159 W, and 28 seconds are merely guidelines – most motherboards should be able to go beyond this, and Intel encourages its partners to adjust these values by default as required. We tested Intel’s guidelines with a 10 minute run of Cinebench R20.
He we can see that at idle, the CPU sits at 5.0 GHz. But immediately when the workload comes on, it has to reduce the average CPU frequency because it goes straight up to the 159W limit – simply put, 159W isn’t enough to hit 5.0 GHz. We see the temperature slowly rise to 92C, but because the power isn’t enough the frequency keeps fluctuating. By the end of the first Cinebench R20 section, it seems that the majority of it occurred during the turbo period. This means that this run scored almost the same as a pure 5.0 GHz run. However the subsequent runs were not as performant. Because the turbo budget had been used up, the processor had to sit at 127 W, its PL1 value. At this power, the processor kept bouncing between 4.6 GHz and 4.7 GHz to find the balance. The temperatures in this mode kept stable, nearer 80C, but the performance of Cinebench R20 dropped around 8-10% because the CPU was now limited by its PL1/TDP value, as per Intel’s base configuration recommendation. Going BeyondBecause motherboard manufactuers can do what they want with these values, we set the task on the motherboard we tested, the MSI Z390 Gaming Edge AC. By default, MSI has set the BIOS for the Core i9-9900KS with a simple equation. PL1 = PL2 = 255 W. When PL1 and PL2 are equal to each other, then Tau doesn’t matter. But what this setting does is state that MSI will allow the processor to consume as much power as it needs to up to 255 W. If it can hit 5.0 GHz before this value (hint, it does), then the user can turbo at 5.0 GHz forever. The only way that this processor will reduce in frequency is either at idle or due to thermal issues. Here’s the same run but done with MSI’s own settings:
The processor stayed at a constant 5.0 GHz through the whole run. The CPU started pulling around 172W on average during the test, fluctuating a little bit based on exactly which 1s and 0s were going through. The CPU temperature is obviously higher, as we used the same cooling setup as before, and peaked at 92C, but the system was fully table the entire time.
Here was our system setup – a 2kg TRUE Copper air cooler powered by an average fan running at full speed in an open test bed. But what this means is that users are going to have to be wary of exactly what settings the motherboard manufacturers are using. For those of you reading this review on the day it goes live, you’ll likely see more than a dozen other reviews testing this chip – each one is likely using a different motherboard, and each one might be using different PL2 and Tau values. What you’ve got here are the two extremes: Intel’s recommendation and MSI’s ‘going to the max’. Be prepared for a range of results. Where time has permitted, we’ve tested both extremes. Our System Test section focuses significantly on real-world testing, user experience, with a slight nod to throughput. In this section we cover application loading time, image processing, simple scientific physics, emulation, neural simulation, optimized compute, and 3D model development, with a combination of readily available and custom software. For some of these tests, the bigger suites such as PCMark do cover them (we publish those values in our office section), although multiple perspectives is always beneficial. In all our tests we will explain in-depth what is being tested, and how we are testing. All of our benchmark results can also be found in our benchmark engine, Bench. Application Load: GIMP 2.10.4One of the most important aspects about user experience and workflow is how fast does a system respond. A good test of this is to see how long it takes for an application to load. Most applications these days, when on an SSD, load fairly instantly, however some office tools require asset pre-loading before being available. Most operating systems employ caching as well, so when certain software is loaded repeatedly (web browser, office tools), then can be initialized much quicker. In our last suite, we tested how long it took to load a large PDF in Adobe Acrobat. Unfortunately this test was a nightmare to program for, and didn’t transfer over to Win10 RS3 easily. In the meantime we discovered an application that can automate this test, and we put it up against GIMP, a popular free open-source online photo editing tool, and the major alternative to Adobe Photoshop. We set it to load a large 50MB design template, and perform the load 10 times with 10 seconds in-between each. Due to caching, the first 3-5 results are often slower than the rest, and time to cache can be inconsistent, we take the average of the last five results to show CPU processing on cached loading.
The 9900KS hits the top of all the consumer processors in our app loading test. FCAT: Image ProcessingThe FCAT software was developed to help detect microstuttering, dropped frames, and run frames in graphics benchmarks when two accelerators were paired together to render a scene. Due to game engines and graphics drivers, not all GPU combinations performed ideally, which led to this software fixing colors to each rendered frame and dynamic raw recording of the data using a video capture device.
The FCAT software takes that recorded video, which in our case is 90 seconds of a 1440p run of Rise of the Tomb Raider, and processes that color data into frame time data so the system can plot an ‘observed’ frame rate, and correlate that to the power consumption of the accelerators. This test, by virtue of how quickly it was put together, is single threaded. We run the process and report the time to completion.
For some reason our default 9900KS run didn't seem to perform properly, but the 9900KS at Intel guidelines did, within the margin of error of the 9900K which also does turbo at 5.0 GHz. 3D Particle Movement v2.1: Brownian MotionOur 3DPM test is a custom built benchmark designed to simulate six different particle movement algorithms of points in a 3D space. The algorithms were developed as part of my PhD., and while ultimately perform best on a GPU, provide a good idea on how instruction streams are interpreted by different microarchitectures. A key part of the algorithms is the random number generation – we use relatively fast generation which ends up implementing dependency chains in the code. The upgrade over the naïve first version of this code solved for false sharing in the caches, a major bottleneck. We are also looking at AVX2 and AVX512 versions of this benchmark for future reviews. For this test, we run a stock particle set over the six algorithms for 20 seconds apiece, with 10 second pauses, and report the total rate of particle movement, in millions of operations (movements) per second. We have a non-AVX version and an AVX version, with the latter implementing AVX512 and AVX2 where possible. 3DPM v2.1 can be downloaded from our server: 3DPMv2.1.rar (13.0 MB)
Without AVX acceleration, the Core i9-9900KS hardware manages to push ahead of the 9900K due to the extra frequency, and even above the 10-core 7900X. Because these are non-AVX instructions, they aren't pushing the CPU as hard as it can be, so we're not really draining the turbo bucket in our 159W PL2 test.
On the other hand, our AVX2 accelerated test is also showing both PL2 settings performing about equal. This test does involve a 10-second delay between each of its six subtests, which allows some turbo budget to be regained. Couple that with the 30 second delay between individual runs, it would appear that there's enough turbo budget for the whole run. Dolphin 5.0: Console EmulationOne of the popular requested tests in our suite is to do with console emulation. Being able to pick up a game from an older system and run it as expected depends on the overhead of the emulator: it takes a significantly more powerful x86 system to be able to accurately emulate an older non-x86 console, especially if code for that console was made to abuse certain physical bugs in the hardware. For our test, we use the popular Dolphin emulation software, and run a compute project through it to determine how close to a standard console system our processors can emulate. In this test, a Nintendo Wii would take around 1050 seconds. The latest version of Dolphin can be downloaded from https://dolphin-emu.org/
Dolphin loves single threaded performance, so we see the 9900 series at the top here. DigiCortex 1.20: Sea Slug Brain SimulationThis benchmark was originally designed for simulation and visualization of neuron and synapse activity, as is commonly found in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron / 1.8B synapse simulation, equivalent to a Sea Slug.
Example of a 2.1B neuron simulation We report the results as the ability to simulate the data as a fraction of real-time, so anything above a ‘one’ is suitable for real-time work. Out of the two modes, a ‘non-firing’ mode which is DRAM heavy and a ‘firing’ mode which has CPU work, we choose the latter. Despite this, the benchmark is still affected by DRAM speed a fair amount. DigiCortex can be downloaded from http://www.digicortex.net/
Interestingly enough the big splot in this benchmark series is here with DigiCortex. I'm not sure what's going on here; not only with the result being low (due to DDR4-2666 compared to AMD's higher support) but also lower than the 9900K. y-Cruncher v0.7.6: Microarchitecture Optimized ComputeI’ve known about y-Cruncher for a while, as a tool to help compute various mathematical constants, but it wasn’t until I began talking with its developer, Alex Yee, a researcher from NWU and now software optimization developer, that I realized that he has optimized the software like crazy to get the best performance. Naturally, any simulation that can take 20+ days can benefit from a 1% performance increase! Alex started y-cruncher as a high-school project, but it is now at a state where Alex is keeping it up to date to take advantage of the latest instruction sets before they are even made available in hardware. For our test we run y-cruncher v0.7.6 through all the different optimized variants of the binary, single threaded and multi-threaded, including the AVX-512 optimized binaries. The test is to calculate 250m digits of Pi, and we use the single threaded and multi-threaded versions of this test. Users can download y-cruncher from Alex’s website: http://www.numberworld.org/y-cruncher/
y-Cruncher can use AVX512 for the HEDT chips, as they are faster than the 9900KS, but all the 9900 series are performing similarly at 5.0 GHz single threaded here. Agisoft Photoscan 1.3.3: 2D Image to 3D Model ConversionOne of the ISVs that we have worked with for a number of years is Agisoft, who develop software called PhotoScan that transforms a number of 2D images into a 3D model. This is an important tool in model development and archiving, and relies on a number of single threaded and multi-threaded algorithms to go from one side of the computation to the other.
In our test, we take v1.3.3 of the software with a good sized data set of 84 x 18 megapixel photos and push it through a reasonably fast variant of the algorithms, but is still more stringent than our 2017 test. We report the total time to complete the process. Agisoft’s Photoscan website can be found here: http://www.agisoft.com/
Agisoft is a more variable workload, so there will be bits here and there where both processors can fully go to 5.0 GHz turbo and recover budget. The 12-core AMD chip is ahead, and both 9900KS settings are almost equal. They are both ahead of the normal 9900K by just over 10%. Rendering is often a key target for processor workloads, lending itself to a professional environment. It comes in different formats as well, from 3D rendering through rasterization, such as games, or by ray tracing, and invokes the ability of the software to manage meshes, textures, collisions, aliasing, physics (in animations), and discarding unnecessary work. Most renderers offer CPU code paths, while a few use GPUs and select environments use FPGAs or dedicated ASICs. For big studios however, CPUs are still the hardware of choice. All of our benchmark results can also be found in our benchmark engine, Bench. Corona 1.3: Performance RenderAn advanced performance based renderer for software such as 3ds Max and Cinema 4D, the Corona benchmark renders a generated scene as a standard under its 1.3 software version. Normally the GUI implementation of the benchmark shows the scene being built, and allows the user to upload the result as a ‘time to complete’.
We got in contact with the developer who gave us a command line version of the benchmark that does a direct output of results. Rather than reporting time, we report the average number of rays per second across six runs, as the performance scaling of a result per unit time is typically visually easier to understand. The Corona benchmark website can be found at https://corona-renderer.com/benchmark
Interestingly both 9900KS settings performed slightly worse than the 9900K here, which you wouldn't expect given the all-core turbo being higher. It would appear that there is something else the bottleneck in this test. Blender 2.79b: 3D Creation SuiteA high profile rendering tool, Blender is open-source allowing for massive amounts of configurability, and is used by a number of high-profile animation studios worldwide. The organization recently released a Blender benchmark package, a couple of weeks after we had narrowed our Blender test for our new suite, however their test can take over an hour. For our results, we run one of the sub-tests in that suite through the command line - a standard ‘bmw27’ scene in CPU only mode, and measure the time to complete the render. Blender can be downloaded at https://www.blender.org/download/
All the 9900 parts and settings perform roughly the same with one another, however the PL2 255W setting on the 9900KS does allow it to get a small ~5% advantage over the standard 9900K. LuxMark v3.1: LuxRender via Different Code PathsAs stated at the top, there are many different ways to process rendering data: CPU, GPU, Accelerator, and others. On top of that, there are many frameworks and APIs in which to program, depending on how the software will be used. LuxMark, a benchmark developed using the LuxRender engine, offers several different scenes and APIs. In our test, we run the simple ‘Ball’ scene on both the C++ and OpenCL code paths, but in CPU mode. This scene starts with a rough render and slowly improves the quality over two minutes, giving a final result in what is essentially an average ‘kilorays per second’.
Both 9900KS settings perform equally well here, and a sizeable jump over the standard 9900K. POV-Ray 3.7.1: Ray TracingThe Persistence of Vision ray tracing engine is another well-known benchmarking tool, which was in a state of relative hibernation until AMD released its Zen processors, to which suddenly both Intel and AMD were submitting code to the main branch of the open source project. For our test, we use the built-in benchmark for all-cores, called from the command line. POV-Ray can be downloaded from http://www.povray.org/
One of the biggest differences between the two power settings is in POV-Ray, with a marked frequency difference. In fact, the 159W setting on the 9900KS puts it below our standard settings for the 9900K, which likely had an big default turbo budget on the board it was on at the time. With the rise of streaming, vlogs, and video content as a whole, encoding and transcoding tests are becoming ever more important. Not only are more home users and gamers needing to convert video files into something more manageable, for streaming or archival purposes, but the servers that manage the output also manage around data and log files with compression and decompression. Our encoding tasks are focused around these important scenarios, with input from the community for the best implementation of real-world testing. All of our benchmark results can also be found in our benchmark engine, Bench. Handbrake 1.1.0: Streaming and Archival Video TranscodingA popular open source tool, Handbrake is the anything-to-anything video conversion software that a number of people use as a reference point. The danger is always on version numbers and optimization, for example the latest versions of the software can take advantage of AVX-512 and OpenCL to accelerate certain types of transcoding and algorithms. The version we use here is a pure CPU play, with common transcoding variations. We have split Handbrake up into several tests, using a Logitech C920 1080p60 native webcam recording (essentially a streamer recording), and convert them into two types of streaming formats and one for archival. The output settings used are:
The 9900KS performed worse than our 9900K in our Handbrake tests, and we're not entirely sure why. It might be related to the regression we saw with DigiCortex. 7-zip v1805: Popular Open-Source Encoding EngineOut of our compression/decompression tool tests, 7-zip is the most requested and comes with a built-in benchmark. For our test suite, we’ve pulled the latest version of the software and we run the benchmark from the command line, reporting the compression, decompression, and a combined score. It is noted in this benchmark that the latest multi-die processors have very bi-modal performance between compression and decompression, performing well in one and badly in the other. There are also discussions around how the Windows Scheduler is implementing every thread. As we get more results, it will be interesting to see how this plays out. Please note, if you plan to share out the Compression graph, please include the Decompression one. Otherwise you’re only presenting half a picture.
Both the 9900KS settings perform identically here, however the Compression test shows a performance regression compared to the standard 9900K. It does make me wonder if there are additional differences between the two chips (such as an internal clock). WinRAR 5.60b3: Archiving ToolMy compression tool of choice is often WinRAR, having been one of the first tools a number of my generation used over two decades ago. The interface has not changed much, although the integration with Windows right click commands is always a plus. It has no in-built test, so we run a compression over a set directory containing over thirty 60-second video files and 2000 small web-based files at a normal compression rate. WinRAR is variable threaded but also susceptible to caching, so in our test we run it 10 times and take the average of the last five, leaving the test purely for raw CPU compute performance.
AES Encryption: File SecurityA number of platforms, particularly mobile devices, are now offering encryption by default with file systems in order to protect the contents. Windows based devices have these options as well, often applied by BitLocker or third-party software. In our AES encryption test, we used the discontinued TrueCrypt for its built-in benchmark, which tests several encryption algorithms directly in memory. The data we take for this test is the combined AES encrypt/decrypt performance, measured in gigabytes per second. The software does use AES commands for processors that offer hardware selection, however not AVX-512.
While more the focus of low-end and small form factor systems, web-based benchmarks are notoriously difficult to standardize. Modern web browsers are frequently updated, with no recourse to disable those updates, and as such there is difficulty in keeping a common platform. The fast paced nature of browser development means that version numbers (and performance) can change from week to week. Despite this, web tests are often a good measure of user experience: a lot of what most office work is today revolves around web applications, particularly email and office apps, but also interfaces and development environments. Our web tests include some of the industry standard tests, as well as a few popular but older tests. We have also included our legacy benchmarks in this section, representing a stack of older code for popular benchmarks. All of our benchmark results can also be found in our benchmark engine, Bench. WebXPRT 3: Modern Real-World Web Tasks, including AIThe company behind the XPRT test suites, Principled Technologies, has recently released the latest web-test, and rather than attach a year to the name have just called it ‘3’. This latest test (as we started the suite) has built upon and developed the ethos of previous tests: user interaction, office compute, graph generation, list sorting, HTML5, image manipulation, and even goes as far as some AI testing. For our benchmark, we run the standard test which goes through the benchmark list seven times and provides a final result. We run this standard test four times, and take an average. Users can access the WebXPRT test at http://principledtechnologies.com/benchmarkxprt/webxprt/
WebXPRT 2015: HTML5 and Javascript Web UX TestingThe older version of WebXPRT is the 2015 edition, which focuses on a slightly different set of web technologies and frameworks that are in use today. This is still a relevant test, especially for users interacting with not-the-latest web applications in the market, of which there are a lot. Web framework development is often very quick but with high turnover, meaning that frameworks are quickly developed, built-upon, used, and then developers move on to the next, and adjusting an application to a new framework is a difficult arduous task, especially with rapid development cycles. This leaves a lot of applications as ‘fixed-in-time’, and relevant to user experience for many years. Similar to WebXPRT3, the main benchmark is a sectional run repeated seven times, with a final score. We repeat the whole thing four times, and average those final scores.
Speedometer 2: JavaScript FrameworksOur newest web test is Speedometer 2, which is a accrued test over a series of javascript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles. Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics. We report this final score.
Google Octane 2.0: Core Web ComputeA popular web test for several years, but now no longer being updated, is Octane, developed by Google. Version 2.0 of the test performs the best part of two-dozen compute related tasks, such as regular expressions, cryptography, ray tracing, emulation, and Navier-Stokes physics calculations. The test gives each sub-test a score and produces a geometric mean of the set as a final result. We run the full benchmark four times, and average the final results.
Mozilla Kraken 1.1: Core Web ComputeEven older than Octane is Kraken, this time developed by Mozilla. This is an older test that does similar computational mechanics, such as audio processing or image filtering. Kraken seems to produce a highly variable result depending on the browser version, as it is a test that is keenly optimized for. The main benchmark runs through each of the sub-tests ten times and produces an average time to completion for each loop, given in milliseconds. We run the full benchmark four times and take an average of the time taken.
3DPM v1: Naïve Code Variant of 3DPM v2.1The first legacy test in the suite is the first version of our 3DPM benchmark. This is the ultimate naïve version of the code, as if it was written by scientist with no knowledge of how computer hardware, compilers, or optimization works (which in fact, it was at the start). This represents a large body of scientific simulation out in the wild, where getting the answer is more important than it being fast (getting a result in 4 days is acceptable if it’s correct, rather than sending someone away for a year to learn to code and getting the result in 5 minutes). In this version, the only real optimization was in the compiler flags (-O2, -fp:fast), compiling it in release mode, and enabling OpenMP in the main compute loops. The loops were not configured for function size, and one of the key slowdowns is false sharing in the cache. It also has long dependency chains based on the random number generation, which leads to relatively poor performance on specific compute microarchitectures. 3DPM v1 can be downloaded with our 3DPM v2 code here: 3DPMv2.1.rar (13.0 MB)
x264 HD 3.0: Older Transcode TestThis transcoding test is super old, and was used by Anand back in the day of Pentium 4 and Athlon II processors. Here a standardized 720p video is transcoded with a two-pass conversion, with the benchmark showing the frames-per-second of each pass. This benchmark is single-threaded, and between some micro-architectures we seem to actually hit an instructions-per-clock wall.
Albeit different to most of the other commonly played MMO or massively multiplayer online games, World of Tanks is set in the mid-20th century and allows players to take control of a range of military based armored vehicles. World of Tanks (WoT) is developed and published by Wargaming who are based in Belarus, with the game’s soundtrack being primarily composed by Belarusian composer Sergey Khmelevsky. The game offers multiple entry points including a free-to-play element as well as allowing players to pay a fee to open up more features. One of the most interesting things about this tank based MMO is that it achieved eSports status when it debuted at the World Cyber Games back in 2012.
World of Tanks enCore is a demo application for a new and unreleased graphics engine penned by the Wargaming development team. Over time the new core engine will implemented into the full game upgrading the games visuals with key elements such as improved water, flora, shadows, lighting as well as other objects such as buildings. The World of Tanks enCore demo app not only offers up insight into the impending game engine changes, but allows users to check system performance to see if the new engine run optimally on their system. All of our benchmark results can also be found in our benchmark engine, Bench.
Upon arriving to PC earlier this, Final Fantasy XV: Windows Edition was given a graphical overhaul as it was ported over from console, fruits of their successful partnership with NVIDIA, with hardly any hint of the troubles during Final Fantasy XV's original production and development. In preparation for the launch, Square Enix opted to release a standalone benchmark that they have since updated. Using the Final Fantasy XV standalone benchmark gives us a lengthy standardized sequence to record, although it should be noted that its heavy use of NVIDIA technology means that the Maximum setting has problems - it renders items off screen. To get around this, we use the standard preset which does not have these issues.
Square Enix has patched the benchmark with custom graphics settings and bugfixes to be much more accurate in profiling in-game performance and graphical options. For our testing, we run the standard benchmark with a FRAPs overlay, taking a 6 minute recording of the test. All of our benchmark results can also be found in our benchmark engine, Bench.
Next up is Middle-earth: Shadow of War, the sequel to Shadow of Mordor. Developed by Monolith, whose last hit was arguably F.E.A.R., Shadow of Mordor returned them to the spotlight with an innovative NPC rival generation and interaction system called the Nemesis System, along with a storyline based on J.R.R. Tolkien's legendarium, and making it work on a highly modified engine that originally powered F.E.A.R. in 2005.
Using the new LithTech Firebird engine, Shadow of War improves on the detail and complexity, and with free add-on high-resolution texture packs, offers itself as a good example of getting the most graphics out of an engine that may not be bleeding edge. All of our benchmark results can also be found in our benchmark engine, Bench.
Seen as the holy child of DirectX12, Ashes of the Singularity (AoTS, or just Ashes) has been the first title to actively go explore as many of the DirectX12 features as it possibly can. Stardock, the developer behind the Nitrous engine which powers the game, has ensured that the real-time strategy title takes advantage of multiple cores and multiple graphics cards, in as many configurations as possible.
As a real-time strategy title, Ashes is all about responsiveness during both wide open shots but also concentrated battles. With DirectX12 at the helm, the ability to implement more draw calls per second allows the engine to work with substantial unit depth and effects that other RTS titles had to rely on combined draw calls to achieve, making some combined unit structures ultimately very rigid. Stardock clearly understand the importance of an in-game benchmark, ensuring that such a tool was available and capable from day one, especially with all the additional DX12 features used and being able to characterize how they affected the title for the developer was important. The in-game benchmark performs a four minute fixed seed battle environment with a variety of shots, and outputs a vast amount of data to analyze. For our benchmark, we run Ashes Classic: an older version of the game before the Escalation update. The reason for this is that this is easier to automate, without a splash screen, but still has a strong visual fidelity to test. Ashes has dropdown options for MSAA, Light Quality, Object Quality, Shading Samples, Shadow Quality, Textures, and separate options for the terrain. There are several presents, from Very Low to Extreme: we run our benchmarks at the above settings, and take the frame-time output for our average and percentile numbers. All of our benchmark results can also be found in our benchmark engine, Bench.
Strange Brigade is based in 1903’s Egypt and follows a story which is very similar to that of the Mummy film franchise. This particular third-person shooter is developed by Rebellion Developments which is more widely known for games such as the Sniper Elite and Alien vs Predator series. The game follows the hunt for Seteki the Witch Queen who has arose once again and the only ‘troop’ who can ultimately stop her. Gameplay is cooperative centric with a wide variety of different levels and many puzzles which need solving by the British colonial Secret Service agents sent to put an end to her reign of barbaric and brutality.
The game supports both the DirectX 12 and Vulkan APIs and houses its own built-in benchmark which offers various options up for customization including textures, anti-aliasing, reflections, draw distance and even allows users to enable or disable motion blur, ambient occlusion and tessellation among others. AMD has boasted previously that Strange Brigade is part of its Vulkan API implementation offering scalability for AMD multi-graphics card configurations. All of our benchmark results can also be found in our benchmark engine, Bench.
The highly anticipated iteration of the Grand Theft Auto franchise hit the shelves on April 14th 2015, with both AMD and NVIDIA in tow to help optimize the title. GTA doesn’t provide graphical presets, but opens up the options to users and extends the boundaries by pushing even the hardest systems to the limit using Rockstar’s Advanced Game Engine under DirectX 11. Whether the user is flying high in the mountains with long draw distances or dealing with assorted trash in the city, when cranked up to maximum it creates stunning visuals but hard work for both the CPU and the GPU.
For our test we have scripted a version of the in-game benchmark. The in-game benchmark consists of five scenarios: four short panning shots with varying lighting and weather effects, and a fifth action sequence that lasts around 90 seconds. We use only the final part of the benchmark, which combines a flight scene in a jet followed by an inner city drive-by through several intersections followed by ramming a tanker that explodes, causing other cars to explode as well. This is a mix of distance rendering followed by a detailed near-rendering action sequence, and the title thankfully spits out frame time data. There are no presets for the graphics options on GTA, allowing the user to adjust options such as population density and distance scaling on sliders, but others such as texture/shadow/shader/water quality from Low to Very High. Other options include MSAA, soft shadows, post effects, shadow resolution and extended draw distance options. There is a handy option at the top which shows how much video memory the options are expected to consume, with obvious repercussions if a user requests more video memory than is present on the card (although there’s no obvious indication if you have a low end GPU with lots of GPU memory, like an R7 240 4GB). All of our benchmark results can also be found in our benchmark engine, Bench.
The latest title in Ubisoft's Far Cry series lands us right into the unwelcoming arms of an armed militant cult in Montana, one of the many middles-of-nowhere in the United States. With a charismatic and enigmatic adversary, gorgeous landscapes of the northwestern American flavor, and lots of violence, it is classic Far Cry fare. Graphically intensive in an open-world environment, the game mixes in action and exploration.
Far Cry 5 does support Vega-centric features with Rapid Packed Math and Shader Intrinsics. Far Cry 5 also supports HDR (HDR10, scRGB, and FreeSync 2). We use the in-game benchmark for our data, and report the average/minimum frame rates. All of our benchmark results can also be found in our benchmark engine, Bench.
Aside from keeping up-to-date on the Formula One world, F1 2017 added HDR support, which F1 2018 has maintained; otherwise, we should see any newer versions of Codemasters' EGO engine find its way into F1. Graphically demanding in its own right, F1 2018 keeps a useful racing-type graphics workload in our benchmarks.
We use the in-game benchmark, set to run on the Montreal track in the wet, driving as Lewis Hamilton from last place on the grid. Data is taken over a one-lap race. All of our benchmark results can also be found in our benchmark engine, Bench.
The Intel Core i9-9900KS is Intel’s first consumer level all-core 5.0 GHz processor. Technically Intel has launched an all 5.0 GHz processor before: earlier this year the Core i9-9990XE was launched into the high-frequency trading market, which had 14 cores at 5.0 GHz, but that part is an auction only part for select business partners. What the Core i9-9900KS does is bring the same principle down to a more consumer friendly core count and a more consumer friendly price point. The tray price is set at $513, although it’s likely to be sold for much more than that. Playing To PowerOne of the key elements I wanted to test in this review is how the chip responds to Turbo. As we’ve discussed at length, and confirmed by Intel: the guidelines for the Turbo settings are not set in stone. Intel actively encourages its motherboard partners to increase these settings if the motherboards are over-engineered to be able to do so. This means that a high-end motherboard should be able to give a longer turbo than a cheap board.
A longer turbo might not mean much. When the turbo budget has run out, the system will limit the chip to the TDP setting in the BIOS (which should be the one on the box), and will try and maximise the frequency for the power limit. On a lot of chips, this means you still have a very high frequency, nowhere near the base frequency. But the power limit does have benefits such as acting as a thermal control at least. In our test, we used MSI’s Z390 Gaming Edge AC. It’s a mid-upper motherboard, but it set our Core i9-9900KS to have a TDP and turbo power limit of 255W. Intel’s ‘guidelines’ state a TDP of 127 W and a turbo power limit of 159 W. When comparing the two, there are some distinct advantages for the 255W setting, such as 10%+ performance on rendering, but the 159W setting does afford 10C lower temperatures in those heavy workloads. Ultimately, as the name TDP = Thermal Design Power implies, it all comes down on your ability to cool the chip. For gaming, the turbo budget didn’t seem to matter at all, except in a few tests at super low resolution and settings. One question that does remain however, is which set of results should we keep? The 255W results are what we get out of the box, and the 159W results are only 'Intel guidelines that Intel expects none of the board manufacturers to keep to'. Ideally we keep both, but that's a mess in its own right. Planning Against The CompetitionThere’s no getting around giving Intel kudos for binning enough processors to commercially sell an all-core 5.0 GHz chip. In our benchmarks, we see it steaming ahead of any other consumer grade processor when it comes to single core performance. Users are likely to be able to push that single (or dual) core turbo a bit higher as well, although the power limits should be monitored. It should be noted that in most cases, the Core i9-9900KS either matched or excelled against the previous king of Intel’s consumer desktop line, the Core i9-9900K. There were a few select instances, namely benchmarks like Handbrake, DigiCortex, F1 2018, and 7-zip, where we did see performance regressions that we weren’t expecting. We’re going to have to go back to Intel to see exactly what these are. But they seem confined to very specific workloads.
Overall, the Core i9-9900KS is Intel’s best ever consumer processor. In ST performance metrics, it wins. In variable threaded metrics, it either wins or does really well. In MT performance metrics, it depends on how strong AMD’s 12-core hardware really is, and how multithreaded the calculation really is. As Intel slowly adds AVX-512 to its consumer line, as it is with Ice Lake, then the MT competition is going to be really interesting. Only Available For A Short Time OnlyWhile the Core i9-9990XE is a 14-core 5.0 GHz chip, it is an OEM only part sold by Intel at auction only, whereas the Core i9-9900KS should experience wider availability at retail, albeit for a limited time. Our colleagues at Tom’s Hardware reported that Intel stated in a promotional video that the processor would only be available during the holiday season of 2019 – or at least that the stock level would not be replenished after the holiday season. When we approached Intel asking for confirmation, we were told:
There is no doubt that there will be some CPUs available into 2020, however it would appear that Intel is only making one main batch of hardware, and once it has gone, it has gone. This might make the $513 tray price that Intel is putting on the part a bit of a misnomer, as retailers might take advantage of this. This will take the shine off the Core i9-9900KS a little, as at $529 or so it would easily be recommended over a Core i9-9900K. If it goes to $599 or $649 because of its limited release, then it becomes less of an interesting buy.
Ultimately the Core i9-9900KS is going to end up in the hands of enthusiasts who want nothing more than the best, but don’t want to jump to the high-end desktop platform. Despite the Intel chipsets for consumers, it’s still a shame that these processors only have 16 PCIe 3.0 lanes, given the desire for direct attached PCIe storage in this market. 
Enlarge / Intel will begin producing 10nm products in its Chandler, Arizona, facility as well as the two current 10nm facilities in Oregon and Israel.
Intel's years-long struggle with the 10nm manufacturing process may finally be over. The company told investors last week that its 10nm yields are ahead of expectations for both client and data center products—and it's bringing a new 10nm production facility online, as well. Currently, all 10nm parts are produced in two of the company's plants: Hillsboro, Oregon, and Kiryat Gat, Israel. But beginning next quarter, Intel's fabrication facility in Chandler, Arizona, will also be producing 10nm parts. 
Enlarge / Intel claims 10nm yields are "ahead of expectations" even before bringing the 10nm fab in Arizona online.
Intel Corporation
What we find more interesting than the 10nm recovery is that Intel still seems to be very serious about pivoting away from being a CPU company. Since 1991, the iconic "Intel Inside" logo has referred to the CPU in your computer, but the company sees more potential in investments in storage, software, networking, AI, and the data center. This certainly doesn't mean Intel plans to exit the consumer and server CPU business, but it does herald a large shift in the company's overall focus. The company estimates the TAM—Total Addressable Market, or the maximum revenue if literally every potential customer bought an Intel product—of its traditional PC and server CPU line at $52 billion. However, it sees an additional $220 billion TAM potential in what it calls "Data-centric" products in data center, Internet of Things, and networking market segments.
This means the company intends to continue making its heaviest bets in areas such as Optane storage, hardware Artificial Intelligence acceleration, 5G modems, data center networking, and more. The slide that really drives this commitment home comes from Q2's investor meeting that explicitly shows the company moving from a "protect and defend" strategy to a growth strategy. If this slide were in a sales meeting, it wouldn't say much—but delivered to the company's investors, it gains a bit of gravitas. Most of this was revealed nearly six months ago at the company's May 2019 investor's meeting, but the Q3 investor's meeting last week continues with and strengthens this story for Intel's future growth, with slides more focused on Optane, network, and IoT/Edge market growth than with the traditional PC and server market. The company shows its new "data-centric" market as having already caught up with its traditional PC-centric market, with almost 50% of its Q3 revenue derived from data-centric products. The majority of the operating income (roughly speaking, profit) returns from those products is outpacing the traditional market as well.
We can confirm that Intel's change in focus seems sincere, based on what the company wants most to talk to Ars about. The company does still want to talk about CPUs, but there's an increasing pressure for coverage of its AI, networking, and even software efforts as the company shifts footing. We believe that this change in focus is likely a good one for consumers, assuming Intel finds the market growth it's looking for in new segments. With higher growth and margins in newer ventures, consumers can hope that Intel will make good on its stated intent to relax its protectionist stance in the CPU market along the way. Read More Intel's 10nm process is on track—so is shift in business model - Ars Technica : https://ift.tt/2N0ABWE TOKYO -- Sony, NTT, and Intel will form a partnership to work on 6G mobile network technology, which is expected to be introduced around 2030, the companies announced on Thursday. Fifth-generation networks are only just being switched on, but the trio wants to establish an organization for the sixth generation in the U.S. by next spring. The three partners intend to invite other major global companies to participate, including players from China. One goal is to develop more advanced semiconductors. The initiative might even put to rest complaints about phone battery life: The companies hope to create smartphones that can last up to a year on a single charge. While 5G is already up and running in South Korea and some U.S. cities, and Chinese carriers are about to launch the world's largest 5G network this week, Japanese telecom companies plan to start their new services next spring. Meanwhile, Western companies like U.S. chipmaker Qualcomm, Finland's Nokia and Sweden's Ericsson have raced to the front of the chip competition, with China's Huawei Technologies also snagging patents and building up its development capabilities. Sony and NTT hope to gain an edge by teaming up with Intel. The specifics of 6G chips and telecom standards will be decided in a few years. On a trial basis, NTT has already successfully produced chips that run on light, consuming one-hundredth of the power used by conventional chips. The company aims to use the partnership to speed up progress toward mass production. Read More Beyond 5G: Sony, NTT and Intel to form 6G partnership - Nikkei Asian Review : https://ift.tt/2WqjukgSANTA CLARA, Calif.--(BUSINESS WIRE)--Delivering on the promise of a truly smart and connected world, where we enjoy an environment that improves the way humans live and interact with technology, requires a significant shift in computing, communications and network infrastructure. Nippon Telegraph and Telephone Corporation (NTT), Intel Corporation (Intel) and Sony Corporation (Sony) today announced that they will create a new industry forum, the Innovative Optical and Wireless Network (IOWN1) Global Forum. The global forum’s objective is to accelerate the adoption of a new communication infrastructure that will bring together an all photonics network infrastructure including silicon photonics, edge computing and distributed connected computing to meet our future data and computing requirements through the development of new technologies, frameworks, specifications and reference designs, in areas such as:
Next-generation communications have the potential to improve many aspects of life, ranging from remote healthcare, disaster prevention, education, automated driving, finance, entertainment/sports and industrial manufacturing. IOWN’s aim is to deliver the next generation of communication infrastructure that will allow as many people as possible to take advantage of this future. Technology, telecommunications and other industry organizations will be invited to join the forum. NTT, Intel and Sony, with their industry leadership and expertise in these technology areas, will act as founding members. In the coming months, NTT, Intel and Sony will select the initial board of the IOWN Global Forum to jointly kick off operations. IOWN Global Forum will be based in the U.S., and membership opportunities are currently available to interested parties. More details on IOWN and membership information can be found at http://www.iowngf.org. Fact Sheet: IOWN Global Forum Executive statements: “NTT has a long history in photonics-related R&D and has achieved cutting-edge results in fields like silicon photonics and optoelectronic convergence. Based on these technologies, NTT aims to power the next generation of technology innovation and solve many of today’s societal challenges, such as ever-increasing power consumption. We will bring our leading R&D expertise to foster the photonics revolution and unlock new technologies to ultimately enable a smart world, where technology becomes so ‘natural’ that people are unaware of its presence. NTT is looking forward to collaborating with its best-in-class partners and realizing a smart world.” “Digital transformation and the growth of data is driving an infrastructure build-out that will dwarf the first era of the cloud defined by hyperscale data centers. We are using information technology now in completely new ways that demand we move, store and process data even faster, more securely and often closer to the person using the service. The combination of super-fast networking and pervasive high-performance computing – the edge infrastructure to deliver smart services anywhere, anytime – can only be achieved with a profoundly new mindset shared across a global ecosystem. The IOWN collaboration is an important step forward. A vision of this magnitude can only be achieved with global leaders across industries. Intel is honored to join forces with NTT and Sony in this industry-wide journey to help define the future of technology.” “Based on our Purpose to ‘Fill the world with emotion, through the power of creativity and technology,’ at Sony we work closely with creators to help them realize their vision through technology, and deliver compelling content to their fans around the world. The high-capacity, low-latency, energy efficiency and flexibility that IOWN offers, opens up exciting new possibilities in terms of connecting creators with users, bringing together people with people, and sharing highly realistic entertainment in real time. We are proud to stand together with NTT and Intel as we embark on the establishment of this forum, and look forward to working with them and many other partners going forward, in order to create new value.” About NTT NTT is a global technology and business solutions provider. We help clients grow their business and improve their competitive market position by delivering fully integrated services, including global networks, cybersecurity, managed IT and applications, cloud and datacenter services combined with business consulting and deep industry expertise. As a top-five global technology and business services provider, NTT works with over 80 of the Global Fortune 100 companies and many thousands of other clients and communities to achieve their goals and contribute to a sustainable future. About Intel Intel (NASDAQ: INTC), a leader in the semiconductor industry, is shaping the data-centric future with computing and communications technology that is the foundation of the world’s innovations. The company’s engineering expertise is helping address the world’s greatest challenges as well as helping secure, power and connect billions of devices and the infrastructure of the smart, connected world — from the cloud to the network to the edge and everything in between. Find more information about Intel at newsroom.intel.com and intel.com. About Sony Sony Corporation is a creative entertainment company with a solid foundation of technology. From game and network services to music, pictures, electronics, semiconductors and financial services — Sony’s purpose is to fill the world with emotion through the power of creativity and technology. For more information, visit: http://www.sony.net/. 1 IOWN stands for Innovative Optical and Wireless Network. IOWN is future communications infrastructure to realize a smart world by using cutting-edge technologies like photonics and computing technologies. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others. 
Intel's next-generation Xeon lineup which includes 10nm Ice Lake and 14nm Cooper Lake has been further detailed in a slide showcased by ASUS during an IoT seminar. The new Xeon lineup which is supposed to launch in 2020 would be featuring a series of new technologies along with an increase in the total number of cores and PCIe lanes compared to existing Xeon families. Intel 10nm Ice Lake Xeon With Up To 38 Cores & 270W TDP, 14nm Cooper Lake With Up To 48 Cores & 300W TDP Arriving in 2020Aimed at the Whitley platform, the Intel 10nm Ice Lake and 14nm Cooper Lake would be launching in 2020. The 14nm Cooper Lake Xeons would launch early in Q2 2020 followed by the 10nm Xeon lineup in Q3 2020. Both families would coexist and we could see the Cooper Lake family be more tuned in terms of clock speeds compared to Ice Lake Xeons due to extensive maturation of the 14 nm process node. 
A slide presented by ASUS during their IoT seminar details Intel's 10nm+ Ice Lake and 14nm+++ Cooper Lake Xeon processors (Image Credits: Brianbox via Computerbase)
The new details for both, the Ice Lake Xeon family and the Cooper Lake Xeon family are mentioned below: Intel Xeon 10nm+ Ice Lake-SP/AP Family Intel Ice Lake-SP processors will be available in the third quarter of 2020 and will be based on the 10nm+ process node. We have seen earlier slides say that the Ice Lake family would feature up to 28 cores but the one from ASUS's presentation says that it would actually feature up to 38 cores & 76 threads per socket. The main highlight of Ice Lake-SP processors will be support for PCIe Gen 4 and 8-channel DDR4 memory. The Ice Lake Xeon family would offer up to 64 PCIe Gen 4 lanes and would offer support for 8-channel DDR4 memory clocked at 3200 MHz (16 DIMM per socket with 2nd Gen Persistent memory support). Intel Ice Lake Xeon processors would be based on the brand new Sunny Cove core architecture which delivers an 18% IPC improvement versus the Skylake core architecture that has been around since 2015.
One thing to note is that Intel's 10nm for 2020 is an enhanced node of the original 10nm node that will launch this year. It's marked as 10nm+ and that is specifically what the Ice Lake-SP Xeon line will make use of. Some of the major upgrades that 10nm will deliver include:
Intel Xeon 14nm+++ Cooper Lake-SP/AP Family Moving on to the Cooper Lake Xeon family which is based on the 14nm+++ process node, we are looking at up to 48 cores and 96 threads in a socketed design. The current Cascade Lake-SP family offers up to 28 cores in socketed variants while the Cascade Lake-AP SKUs which come in BGA only, offer up to 56 cores and 112 threads with TDPs as high as 400W. There will also be a 56 core and 112 thread socketed variant in the Cooper Lake family but that is likely to be part of the Xeon-AP line of chips which feature two dies on the same interposer. In a similar fashion, the BGA and LGA parts in the Ice Lake-AP family could also feature more cores than the SP part but they will be dual-die design and not a single monolithic chip like the ones mentioned here. Also, the 38 core configuration for Ice Lake Xeon doesn't make sense since that means there have to be two 19 core dies and the 19 core config itself isn't something that Intel has done before.
In addition to the higher core count, Intel's Cooper Lake line of Xeon Scalable processors is said to offer higher memory bandwidth, higher AI inference & training performance while supporting blfloat16 through Intel's DL Boost framework. The Whitley platform which will be based around the LGA 4189 socket will also feature support for Intel's Ice Lake-SP processors that utilize the 10nm process node. Ice Lake-SP will also launch in 2020, just slightly after the introduction of Cooper Lake-SP. The Whitley platform would offer support for 8 channel DDR4 memory, 64 PCIe Gen 3.0 lanes. Intel Xeon SP Families:
Intel's Sapphire Rapids-SP and Granite Rapids-SP Xeon families for the Eagle Stream platform were also recently detailed and would bring on the post 10nm era for Intel's Xeon segment, offering new capabilities such as PCIe 5.0 and DDR5 memory along with the new Golden and Willow Cove cores that are expected to further leverage Intel's IPC lead in the server market. You can read more here. Share Tweet Submit Read More Intel’s 10nm Ice Lake Xeon With 38 Cores / 76 Threads at 270W, 14nm Cooper Lake Xeon With 48 Cores / 96 Threads at 300W Arriving in 2020 - Wccftech : https://ift.tt/2MXPDfWIntel CPUs can be exploited unless you disable hyper-threading Linux dev claims - TechRadar10/30/2019  Intel processors are vulnerable to exploitation if they are running hyper-threading, and if you want full security for your CPU, you should disable that feature (which will obviously come at a considerable performance hit in some cases). This is according to Greg Kroah-Hartman, a Linux kernel developer who shared his thoughts on security at the Open Source Summit Europe in Lyons (which finishes today), as highlighted by The Register. The problem as outlined by Kroah-Hartman – and indeed others – is that hyper- threading is dangerous territory because of bugs that can be exploited in MDS or Microarchitectural Data Sampling. If that sounds familiar, you might have remembered it from the ZombieLoad episode back in May, where it first came to light along with other MDS-based exploits including Fallout and RIDL. The only way to be truly safe from any potential attack vector along these lines is simply to switch off hyper-threading. Kroah-Hartman said of OpenBSD (an open source security-focused OS): “A year ago they said disable hyper-threading, there’s going to be lots of problems here. They chose security over performance at an earlier stage than anyone else. Disable hyper-threading. That’s the only way you can solve some of these issues. We are slowing down your workloads. Sorry.” Zombie mitigationYou might further recall that when ZombieLoad stumbled onto the scene, Apple advised that the only way Mac users could be sure of ‘full mitigation’ against attacks was not just to apply the relevant security patches, but also to disable hyper- threading (at an up to 40% performance hit for some users, Apple estimated). Hyper-threading, for the uninitiated, is where a CPU core is split into two virtual cores (or threads), and it can help considerably with heavier tasks and workloads requiring multiple cores (AMD calls this simultaneous multi-threading or SMT). But splitting tasks across cores in this manner can lead to potential problems, as Kroah-Hartman explains: “MDS is where one program can read another program’s data. That's a bad thing when you are running in a shared environment such as cloud computing, even between browser tabs. “You can cross virtual machine boundaries with a lot of this. MDS exploits the fact that CPUs are hyper-threaded, with multiple cores on the same die that share caches. When you share caches, you can detect what the other CPU core was doing.” In short, exploiting these vulnerabilities can actually let an attacker steal data from an application that they wouldn’t otherwise be able to access. A further worry is that there are so many of these potential issues and variants of speculative execution attacks therein, that a ton of patching is needed on a pretty constant basis – indeed fixes are still being deployed for the initial Spectre bug from two years ago. That’s why you need to have all the latest security patches for your OS, and the latest BIOS version, although even then, with hyper-threading running there’s the possibility of vulnerabilities which haven’t been found yet lurking in the background. Hence all the advice on being truly secure pointing to disabling hyper-threading. Kroah-Hartman adds: “If you’re not using a supported distro, or a stable long-term kernel, you have an insecure system. It’s that simple. All those embedded devices out there, that are not updated, totally easy to break.” The Internet of Things, of course, has long been a major concern on the security front. Ryzen to the challengeYou may recall that earlier this year, AMD took the time to clarify that its processors are immune to ZombieLoad and these MDS vulnerabilities, and the Linux developer confirmed that using simultaneous multi-threading with AMD chips is indeed a safe option (going by what’s known at the current time, anyway). However, before all Intel processor owners go running for the hills in a panic about flawed security, bear in mind that the actual odds of being targeted by such an attack are likely to be fairly slim outside of the corporate world. It’s not clear how many speculative execution vulnerabilities have actually been leveraged by attackers to good (or rather bad) effect to date, simply because it’s very hard to even detect these intrusions. The average home user probably won’t ever be targeted, but there’s the rub – ‘probably’ is a very different word to ‘definitely’, and it still comes back to the fact that if you want your Intel PC to be truly secure from these kind of attacks, hyper-threading remains a potential hole in your computer’s security. And of course, it’s also worth noting that all this is happening against a backdrop of Intel allegedly bringing hyper-threading to the entire range of its next-gen Comet Lake processors. Read More Intel CPUs can be exploited unless you disable hyper-threading, Linux dev claims - TechRadar : https://ift.tt/2BXYzM1
Intel Brings More Partners Together Under New, Consolidated Program Intel has officially begun its transition to a revamped partner program, Intel Partner Alliance, with this month's launch of its new training portal, Intel Partner University, which aims to equip partners with personalized curricula for technologies and products like IoT and FPGAs. The Santa Clara, Calif.-based company announced plans to revamp its partner programs at the Intel Partner Connect event in March, but this month, the chipmaker began sharing more details for what partners should expect, including a shakeup of the tier program as well as new ways for partners to identify themselves and collaborate with each other. [Related: Jason Kimrey: Intel’s Data-Centric Platform Strategy Is A Winning Hand For Partners ] Intel Partner Alliance, which is set to launch in the second half of 2020, will consolidate multiple partner programs under one umbrella, with the goals of simplifying how partners work with Intel, providing more technical resources to a broader partner base and enabling the creation of new solutions. What follows are the most important changes partners need to know about Intel Partner Alliance, including details for Intel Partner University as well as the forthcoming Intel Solutions Marketplace and how the programs will differ from their predecessors. Yesterday I previewed Intel's Core i9-9900KS - a new flagship mainstream CPU that the company announced back in May at the Computex technology show. It's essentially a cherry-picked or 'binned' Core i9-9900K, with the main difference between the two CPUs being that the new model can hit 5GHz on all cores at the same time during boost. The older CPU could only do this on up to two cores and when all eight cores were loaded, that frequency falls back to 4.7GHz. The question is, just how much faster will it be, is it worth the premium, and can it reign in AMD's current Zen 2 Ryzen CPUs?  In lightly-threaded applications, there's not likely to be much of an improvement seeing as the Core i9-9900K can already hit 5GHz on two cores. Multi-threaded tasks, though, will benefit from a 300MHz Clock speed boost. That's the limit of the advantages, though, and even before we look at the performance numbers, it's fairly clear that Intel is still going to struggle against the might of the 12-core Ryzen 9 3900X in multi-threaded workloads. 
The new CPU will come with a higher TDP of 127W compared to 95W for the Core i9-9900K and is slated to retail for around $513, which is about $40 higher than the current price of the Core i9-9900K. Test system  CPU test system I've rebuilt my test systems so they use cutting-edge components and also fully up to date versions of Windows 10 with the May 1903 update along with all the various security patches - both from motherboard manufacturers and Microsoft as these are known to have impacted on performance making any data obtained prior to these updates incomparable and unrepresentative. I should also point out that I've used 3466MHz memory with all my systems now as this worked with older AMD CPUs as well as new ones, painting them in their best light, especially given memory prices are so low at the moment. You may see slightly better performance using faster memory, but you'll be unlikely to get that working on 1st Gen Ryzen CPUs. Overclocking: I managed to overclock the Core i9-9900KS to 5.1GHz with a vcore of 1.28V. Other CPU overclocks I've included in the graphs include: Ryzen 7 3800X to 4.4GHz, Ryzen 5 3600: 4.25GHz, Ryzen 5 3600X: 4.25GHz, AMD Ryzen 9 3900X: 4.3GHz, AMD Ryzen 7 3700X: 4.3GHz, AMD Ryzen 7 1800X: 4GHz, AMD Ryzen 7 2700X: 4.2GHz, AMD Threadripper 2920X: 4.2GHz, Intel Core i9-9900K: 5GHz, Intel Core i7-9700K: 5.1GHz, Intel Core i5-9600K: 5GHz, Intel Core i7-8700K: 5GHz. Common components: Corsair Vengeance RGB Pro 3466MHz memory, Nvidia RTX 2070 Super, Samsung 970 Evo 2TB M.2 SSD, EK Waterblocks EK-MLC Phoenix 240 liquid cooler, Corsair RM850i PSU AMD systems Socket AM4: MSI X470 Gaming Pro Carbon AC (Ryzen 7 1800X), Gigabyte X570 Aorus Master (2nd and 3rd Gen Ryzen) Socket TR4: MSI MEG X399 Creation (Threadripper 2920X) Intel systems: LGA1151: MSI MEG Z390 Ace LGA2066: MSI MEG X299 Creation Gaming Benchmarks Shadow of the Tomb Raider I use the built-in benchmark results here as it provides an in-depth look at performance, but it does use a 95th percentile rather than the 99th percentile I use in my other games' manual tests. The difference is usually negligible, but bear that in mind. Intel was strong already here but even at 1080p with a $500 graphics card, the wasn't much more to be had from the higher frequencies, yet plenty of scaling further down the graph moving up through the ranks. The Core i9-9900KS is faster, but only by a few frames per second compared to the Core i9-9900K. 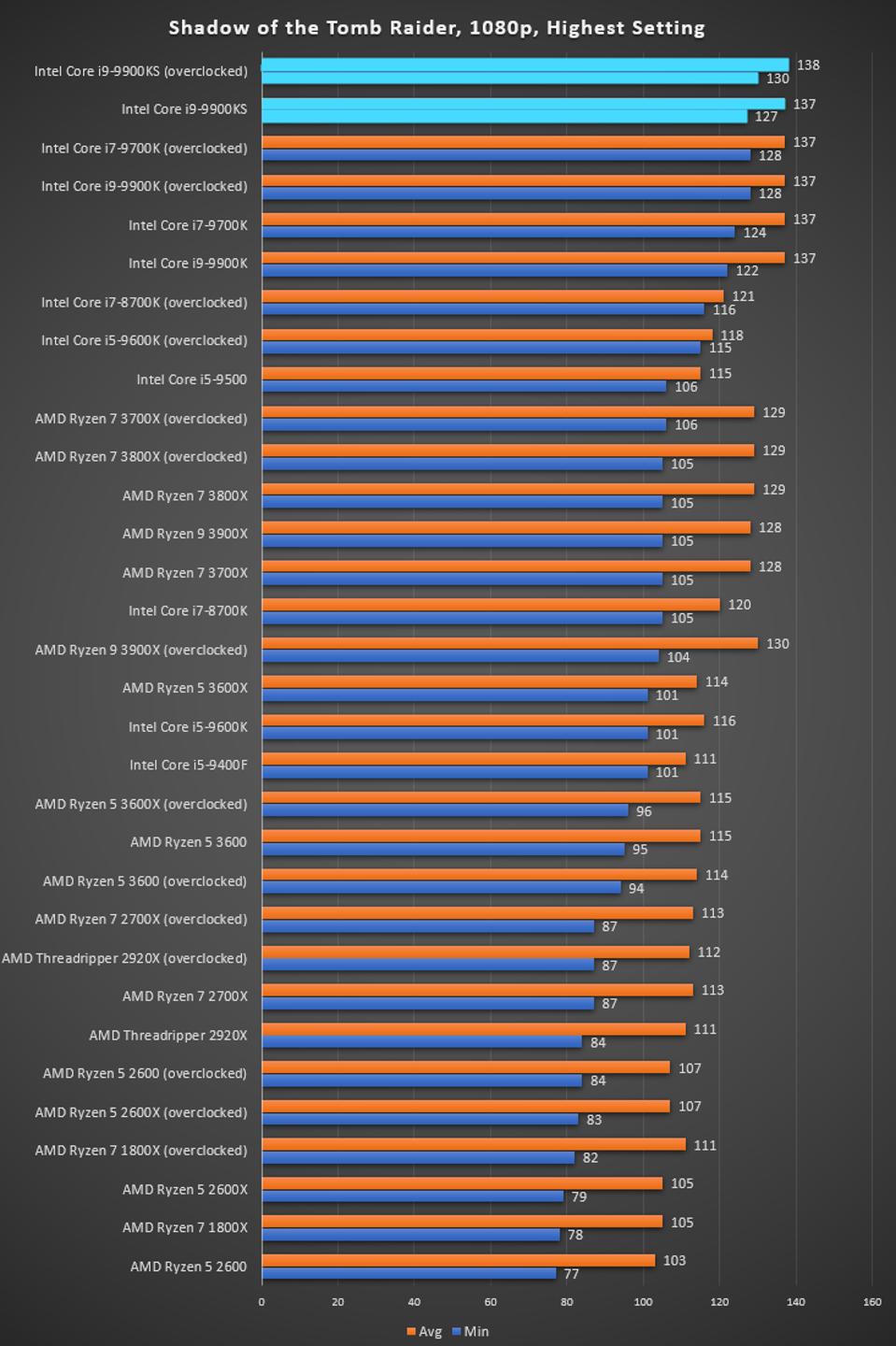
Far Cry 5 The Core i9-9900KS was noticeably quicker than the Core i9-9900K here adding 4fps to the 99th percentile minimum frame rate, but not much to the average. Overclocking the new CPU also saw it leapfrog AMD's 8 and 12-core Zen 2 CPUs, but only by single digit frame rates. 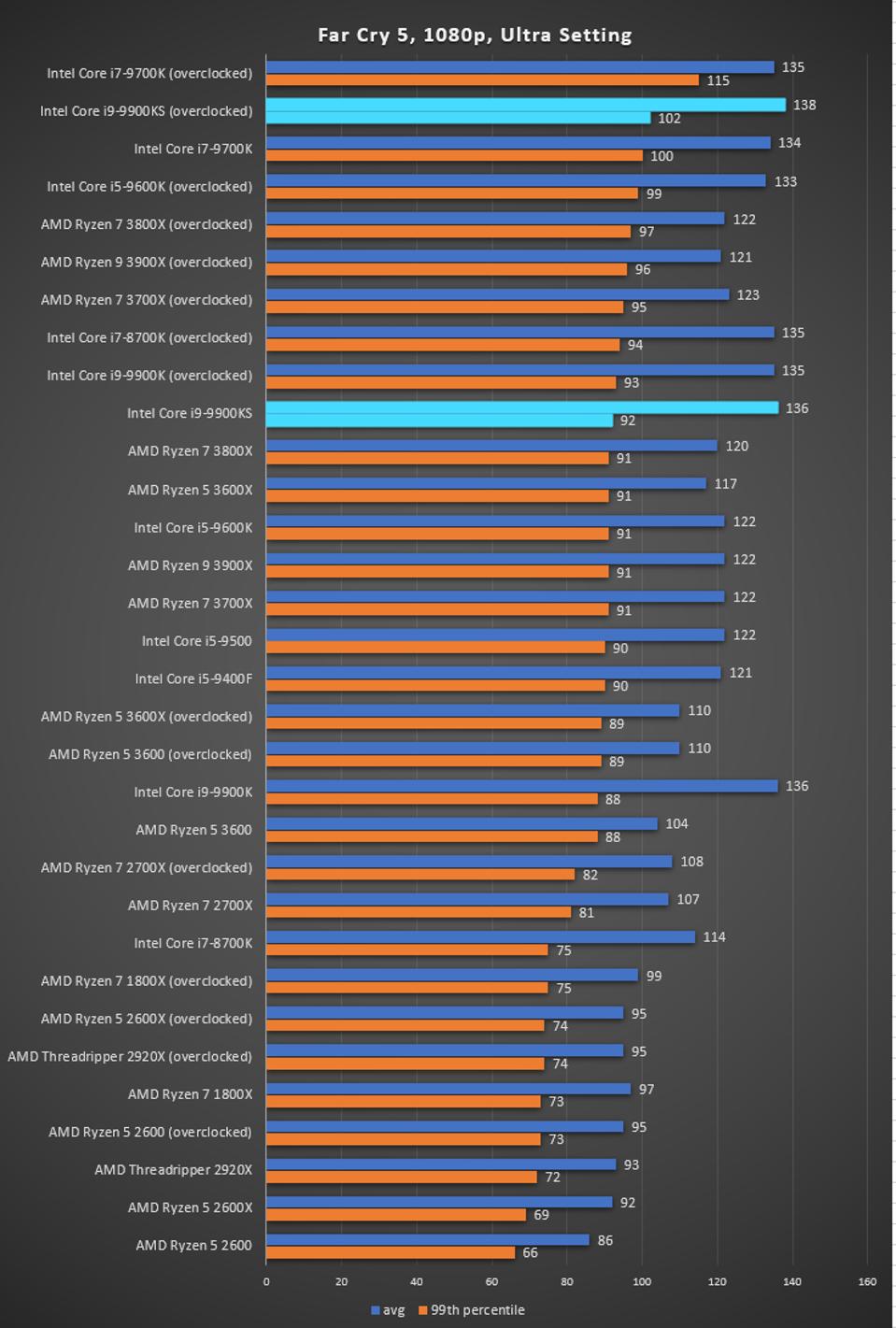
Dota 2 The higher frequencies and lower latency offered by the Core i9-9900KS certainly seems to build on Intel's dominance in DotA 2m albeit with tiny gains at stock speed over the Core i9-9900K. Only when overclocked did it edge out much of a lead. 
Dota 2 is an easy game to run but is a good example of what happens at high frame rates that are likely to appeal to those with high refresh rate monitors. Content creation benchmarks Adobe Premiere Pro The Ryzen 9 3900X is still king for your cash here, knocking at least 10 seconds off the Core i9-9900K's export time of this this comparatively short 4K project. It's also worth noting that the much cheaper Ryzen 7 3800X performed similarly to the new Intel CPU so for Premiere, it's clear where your cash should go. 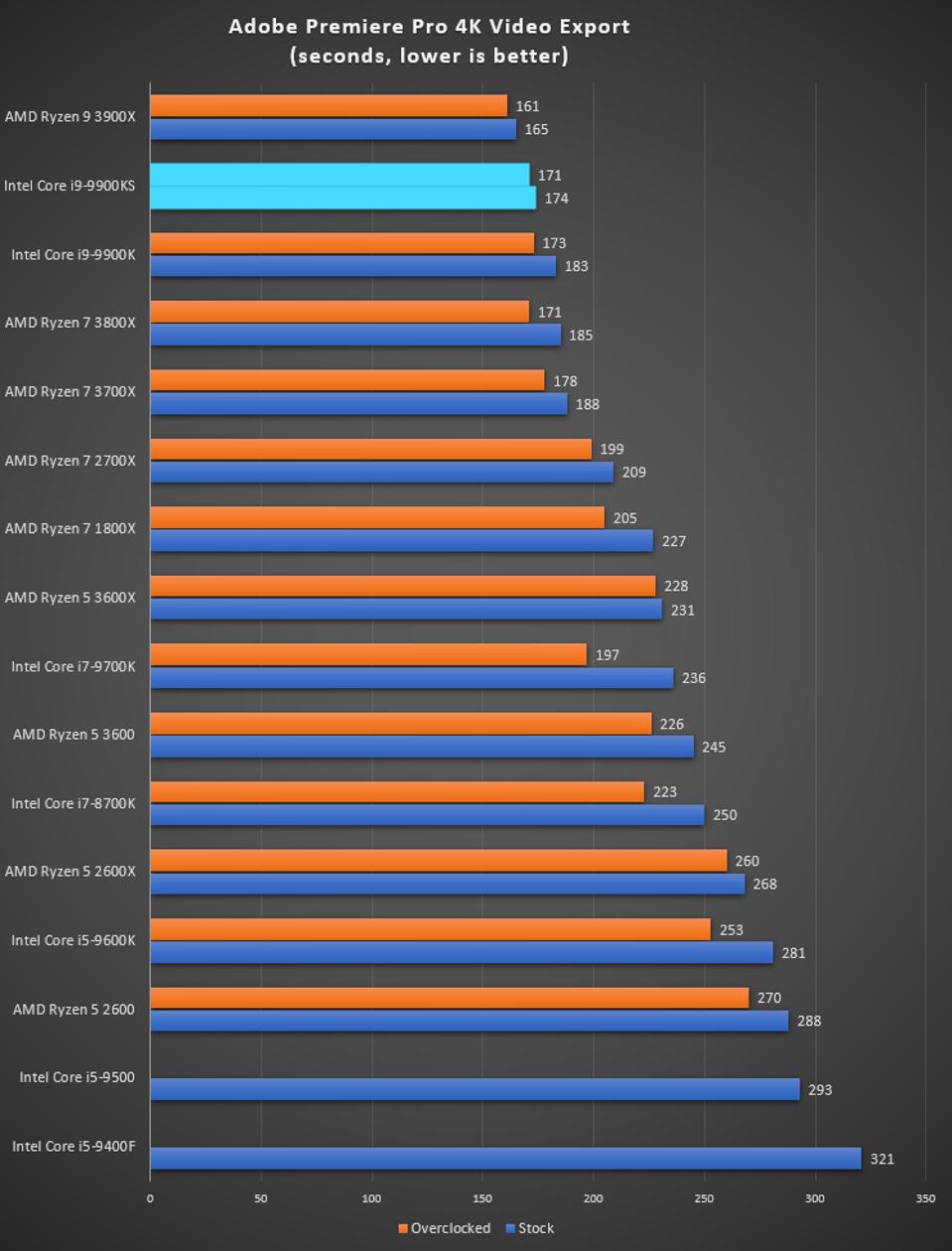
Cinebench R20 The Ryzen 9 3900X still holds on to its single-threaded performance crown in Cinebench R20, but only just. However, it's clear that Intel will need to do more here to get anywhere near what AMD offers in bang for your buck as getting all cores up to 5GHz on the Core i9-9900KS only added a couple of hundred points to the score of the Core i9-9900K while the Ryzen 9 3900X was a couple of thousand points ahead. 
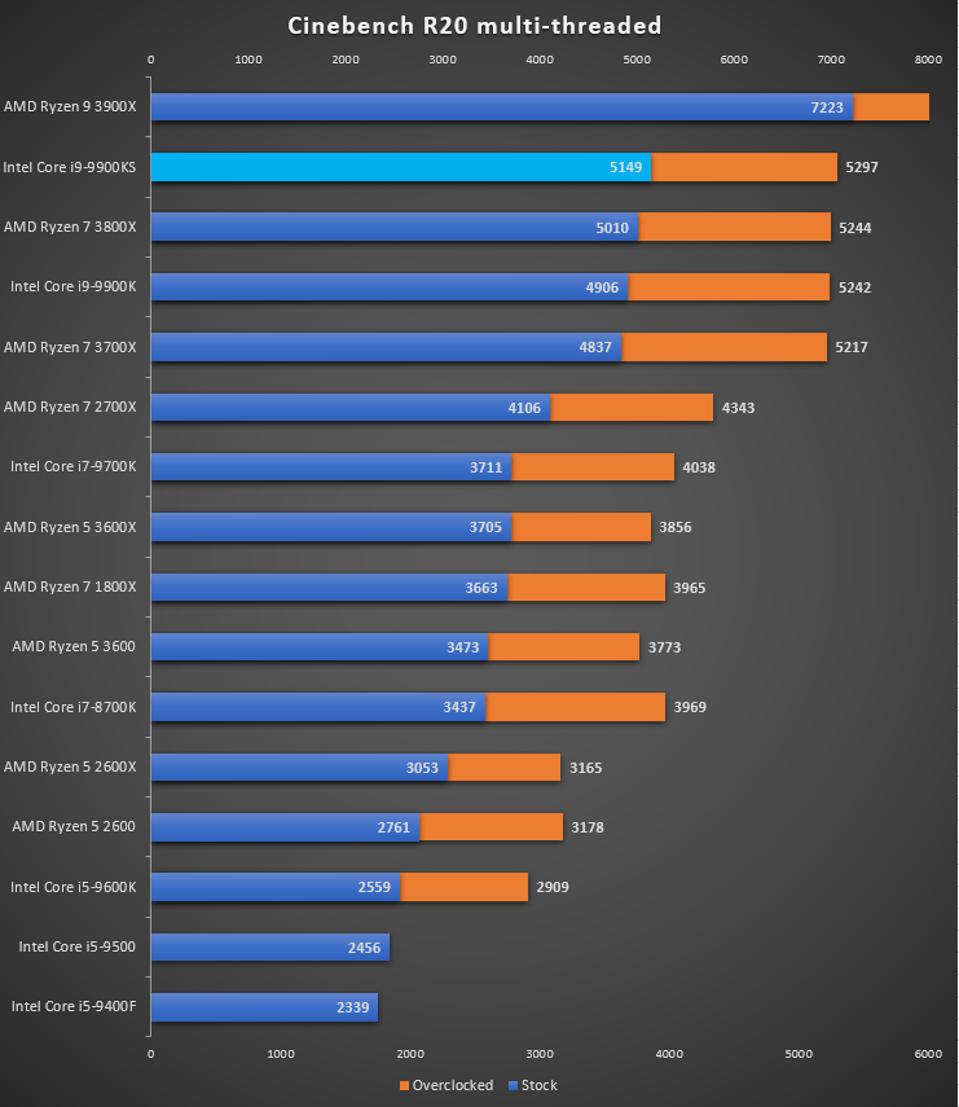
HandBrake Again, it's small gains with the new Intel CPU - certainly not enough to warrant an upgrade and nowhere near enough to dislodge the Ryzen 9 3900X 
PC Mark 10 Image Editing There were some reasonable gains in the PCMark 10 image editing test and these are edging towards justifying the extra premium the Core i9-9900KS demands over the 9900K. However, if cintent creation is your primary concern, it's AMD that deserves your cash still. 
Power Consumption The stock speed power consumption rose by over 50W from the stock CPU, but that's to be expected due to the higher stock speed frequency and different BIOS, which seemed to push the Core i9-9900KS to 5GHz most of the time.  Conclusion While Intel is clearly having some fun here and cherry-picking the very best silicone to offer a faster product - that's essentially all the Core i9-9900KS is - a cherry-picked, special edition that may or may not be widely available depending just how many cherry-pickable dies it's able to produce. There's no real change to my recommendation compared to AMD's offerings - it's just not quick enough compared to the Core i9-9900K to swing things in Intel's favor, at least in content creation. Games are a different matter, though, and there are some noticeable gains here, but they'll only concern you if you were in the market for a Core i9-9900K anyway. If that's you, the price difference may well be worth shelling out for - just - as soon as that difference tops $50 or so, which initial pricing is suggesting, the Core i9-9900K becomes better value, especially if you're willing to overclock it. For its mainstream lineup at least, we'll have to wait for 10th generation CPUs to land for anything more noteworthy from Intel. Check out my other recent CPU reviews Follow me here on Forbes or Twitter, Facebook, YouTube, Instagram or Reddit for more PC hardware news and reviews. Read More Intel’s Fastest Ever Mainstream Processor Reviewed: Is The Core i9-9900KS An AMD Ryzen Killer? - Forbes : https://ift.tt/2PrKi29 |
AuthorWrite something about yourself. No need to be fancy, just an overview. Archives
January 2020
Categories |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
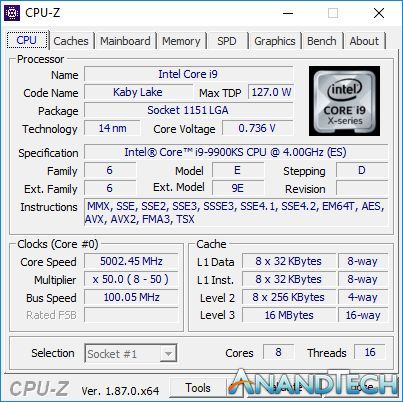










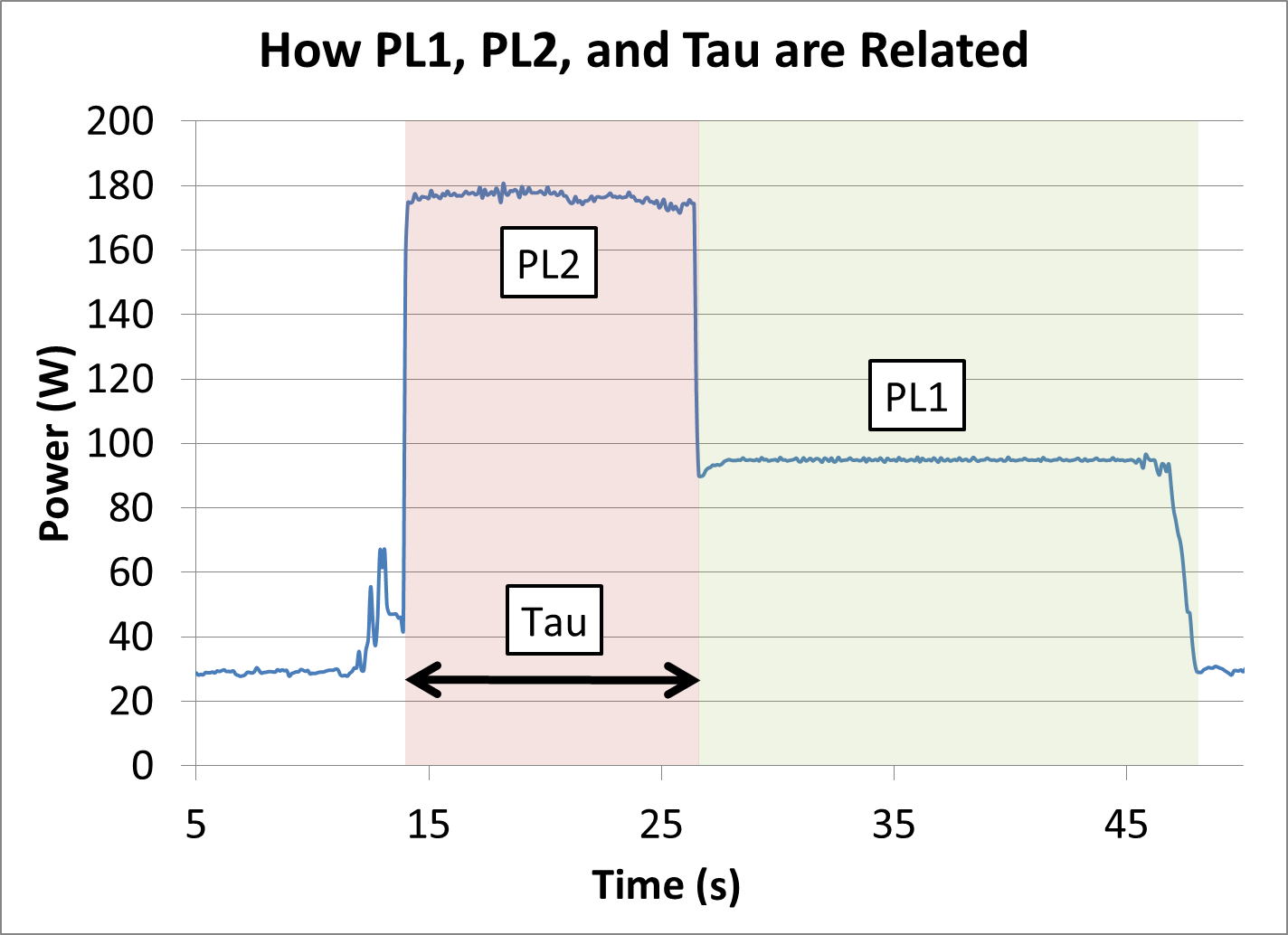
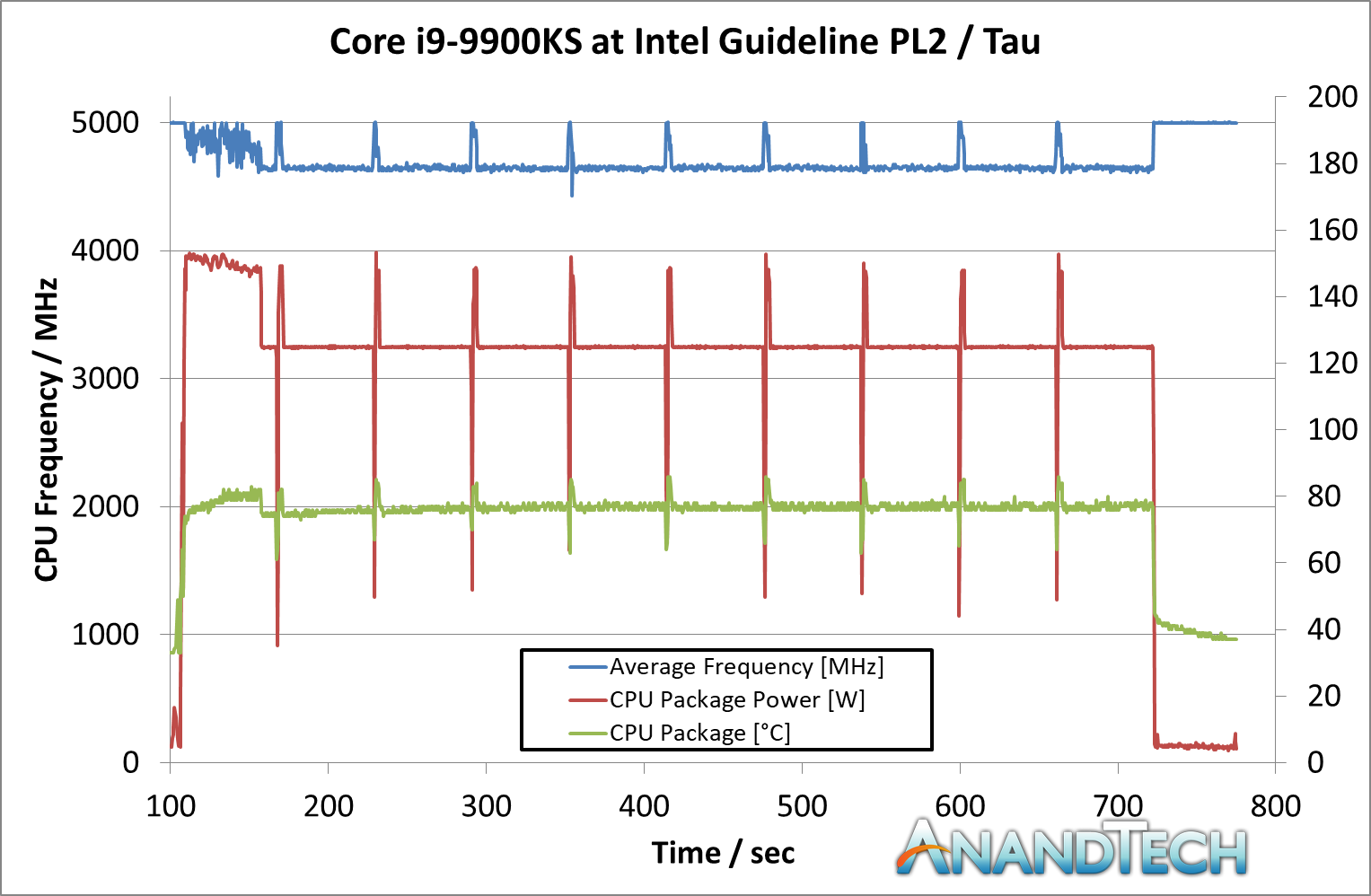



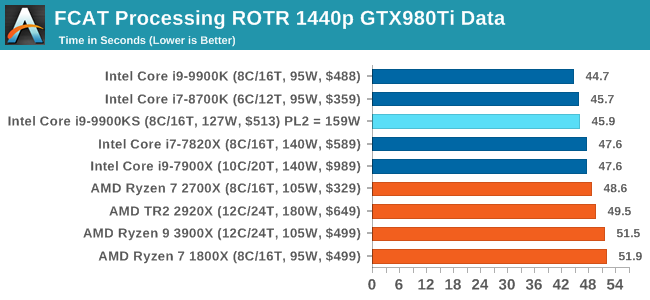
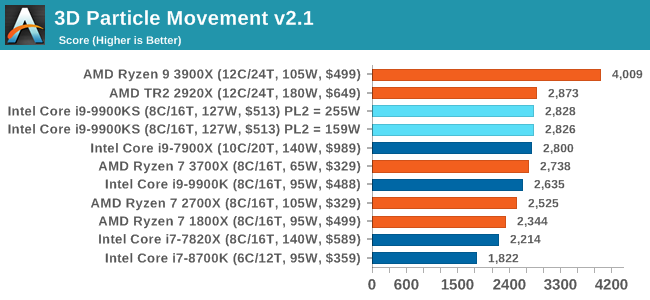
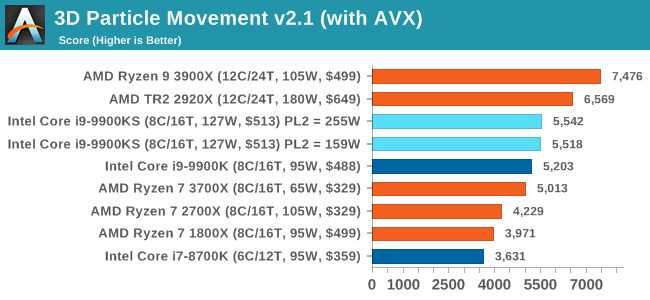

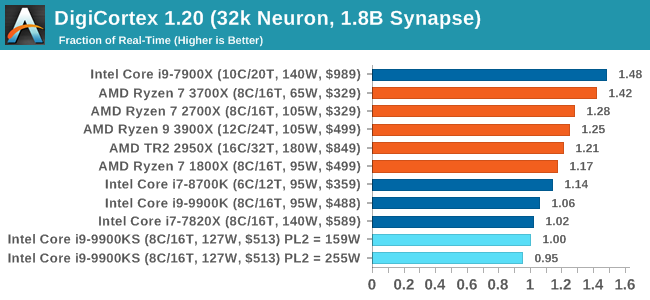
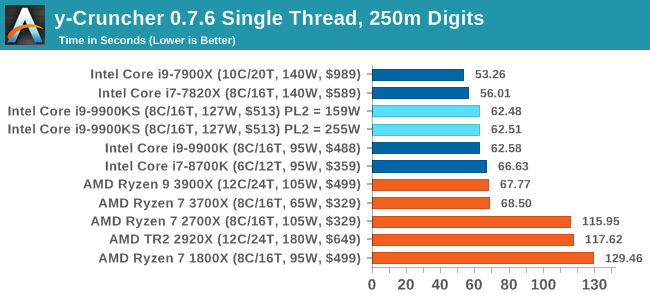


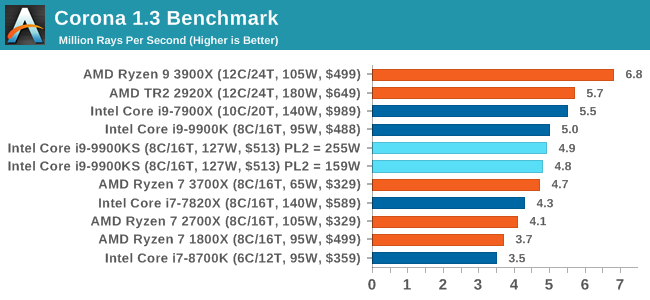
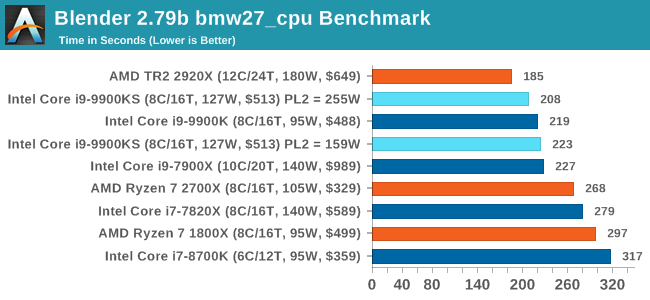
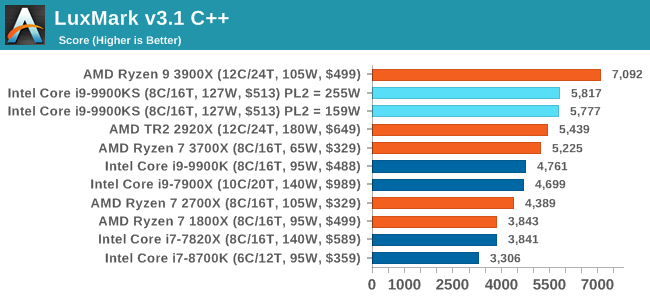
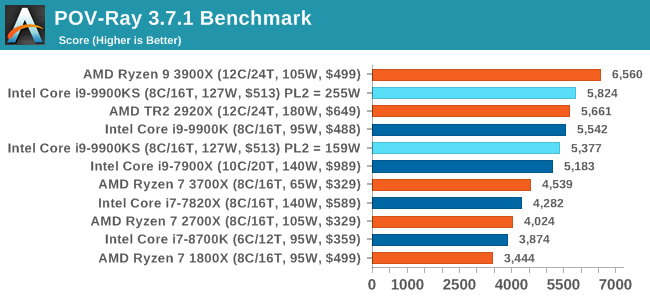
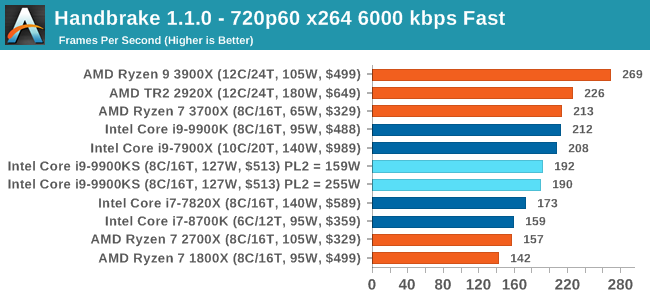
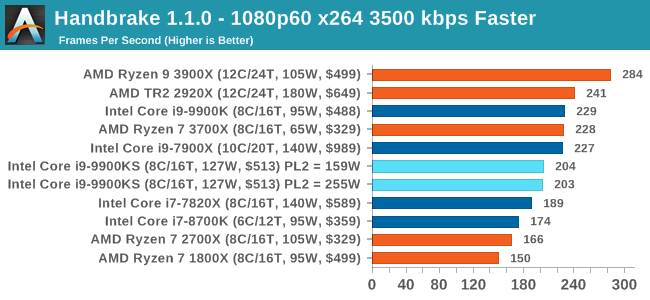
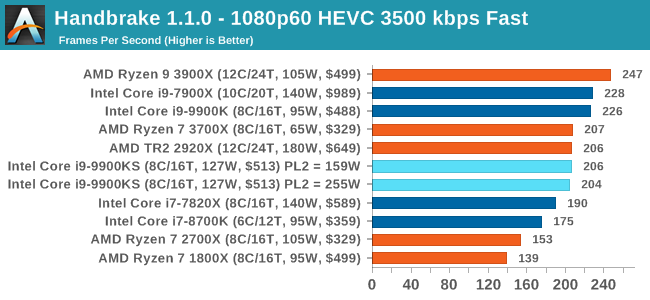
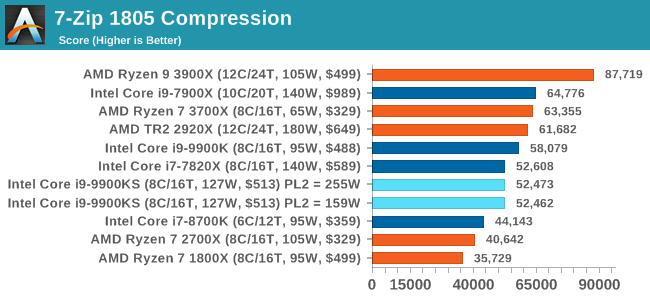
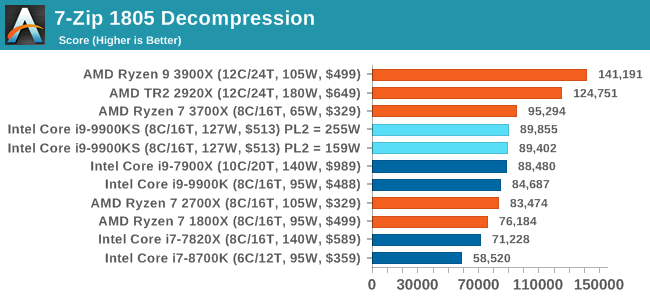
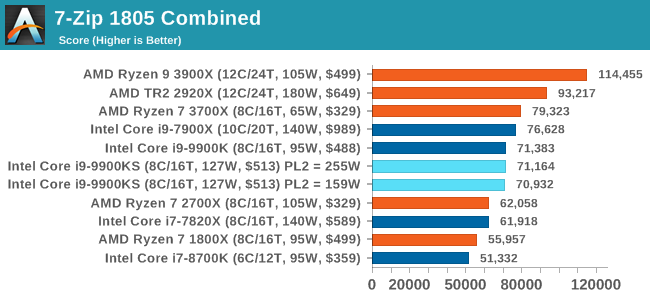
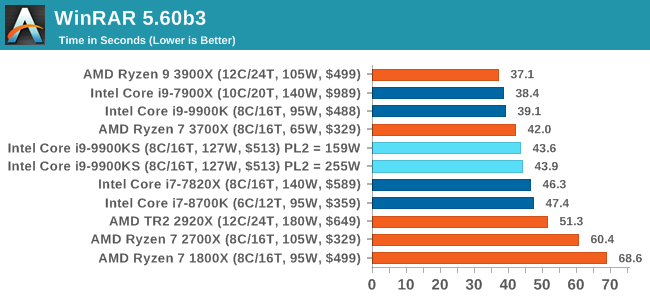

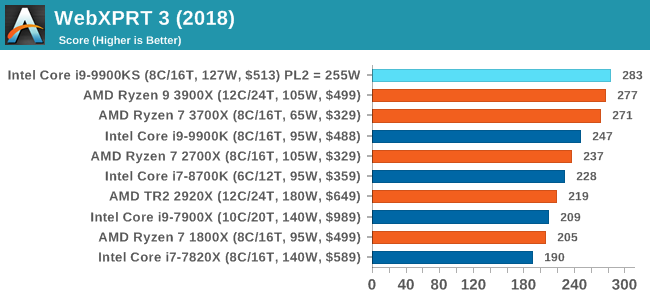
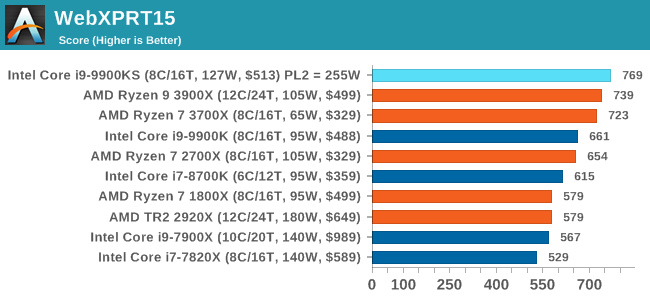
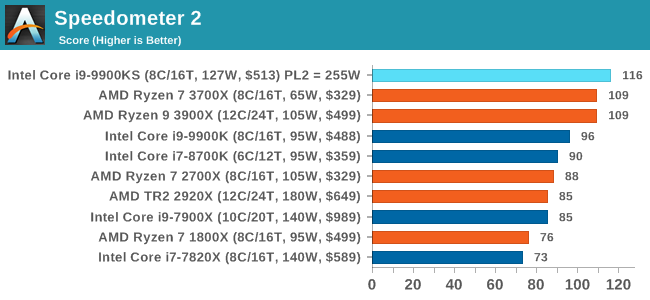
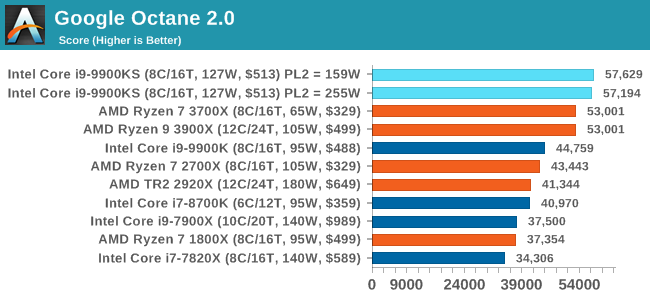
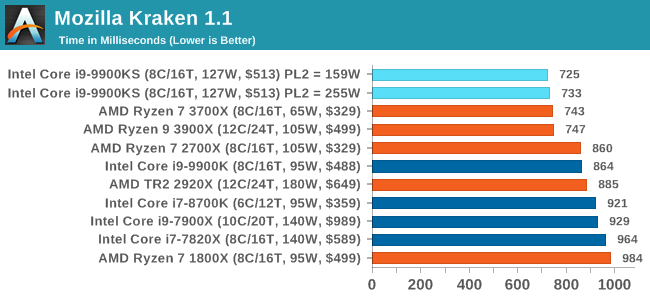
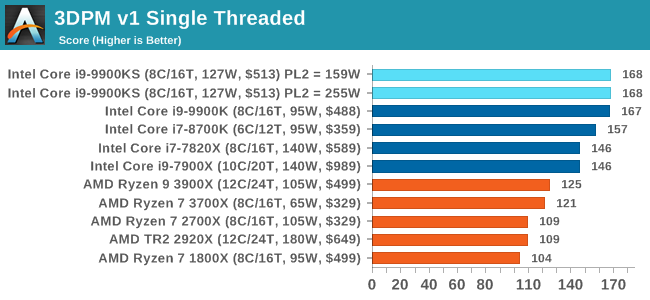
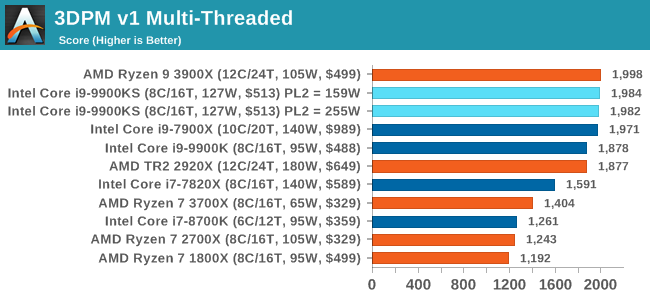
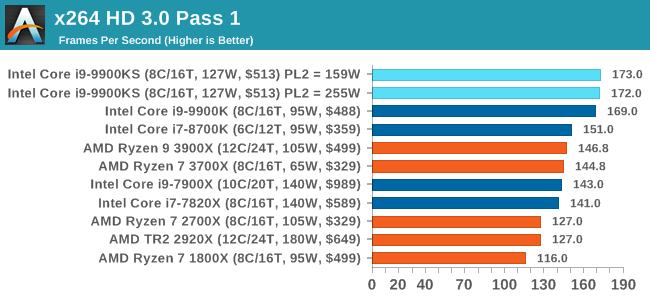


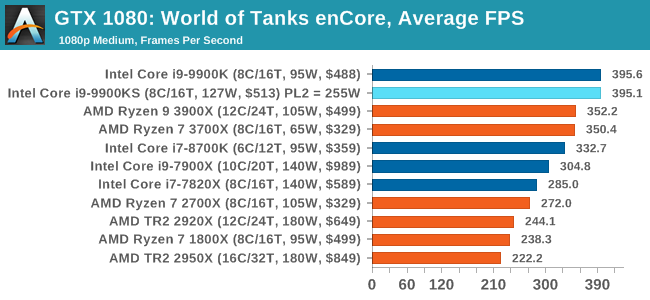
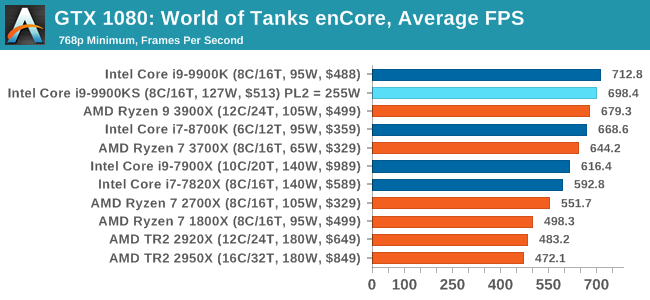
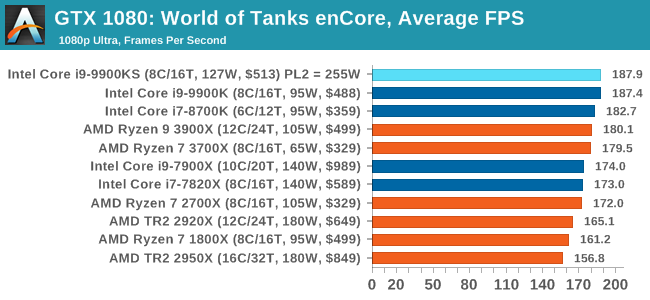
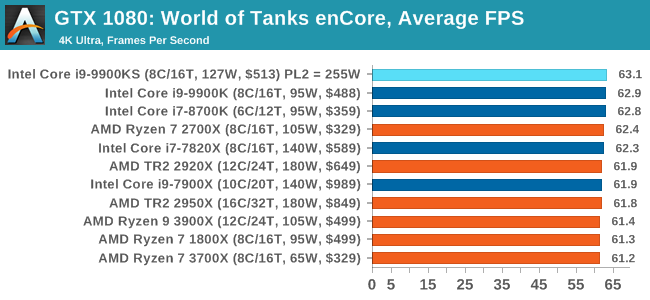
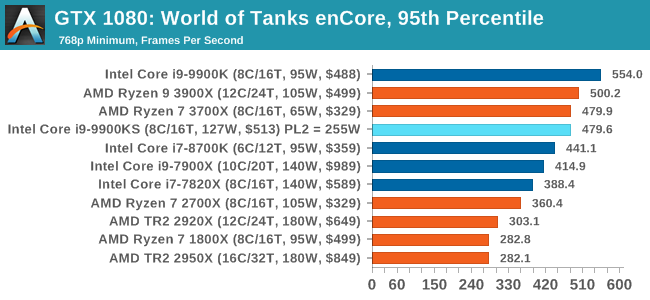
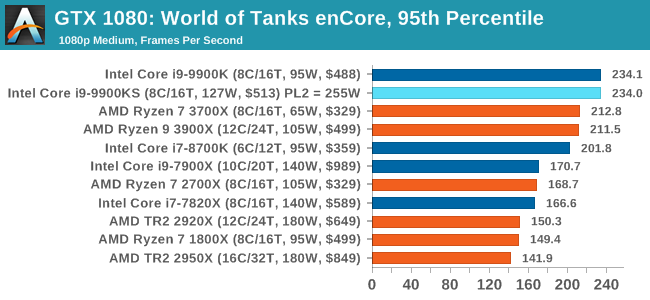
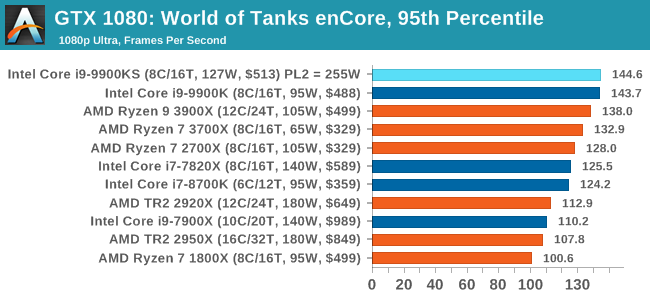
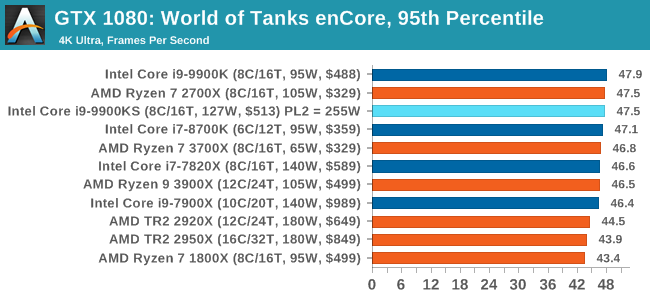

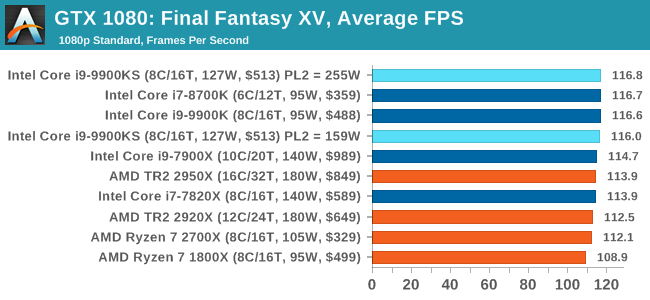
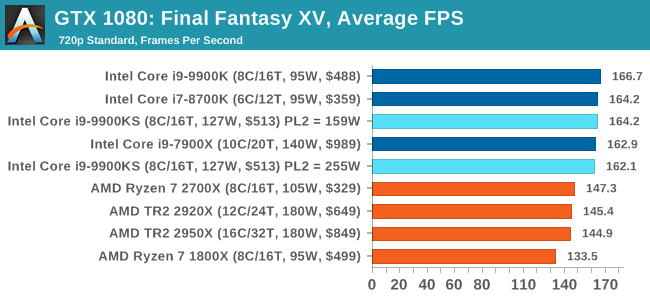


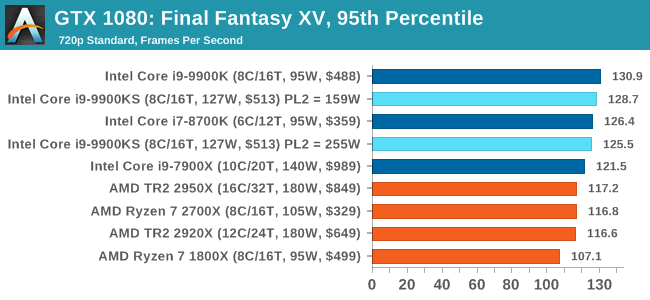
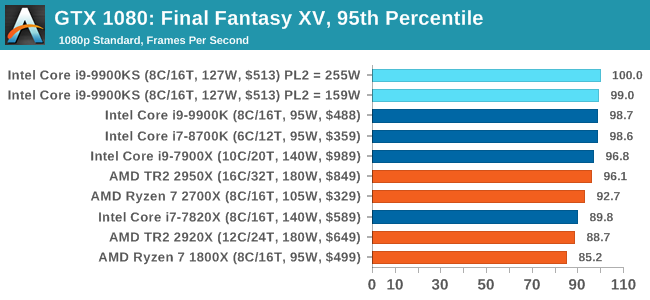
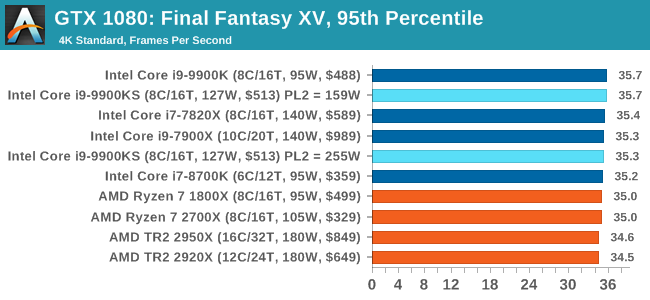
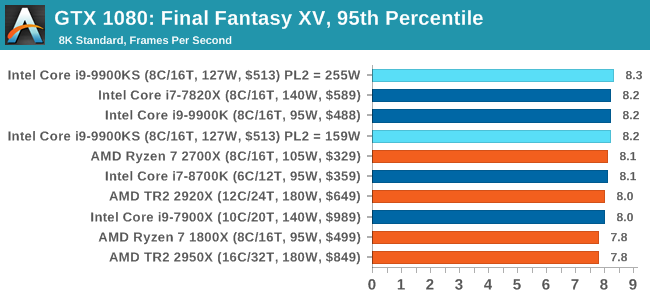

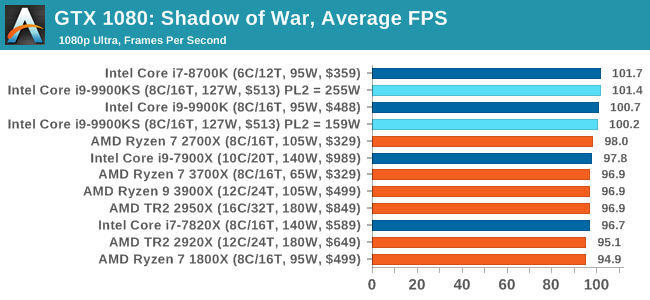
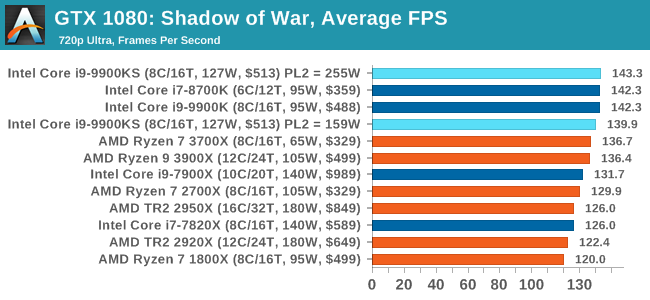
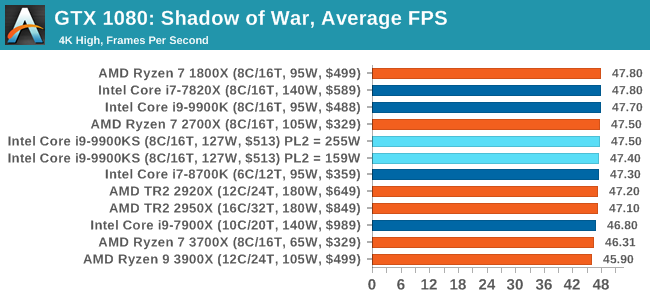
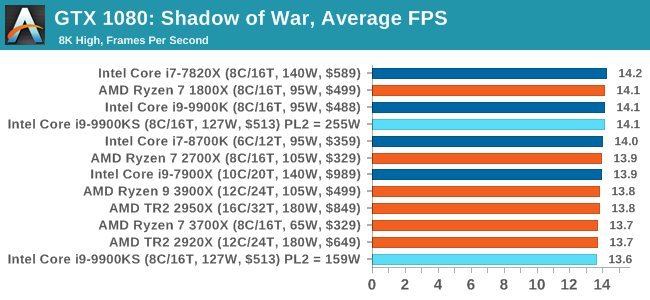

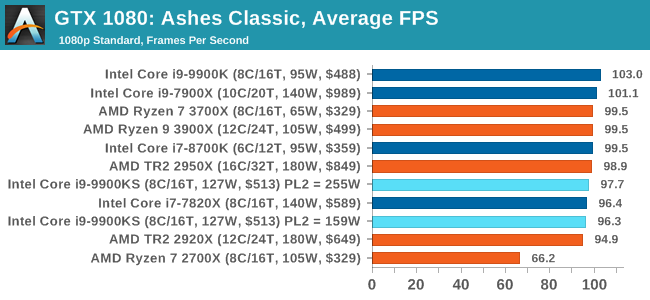
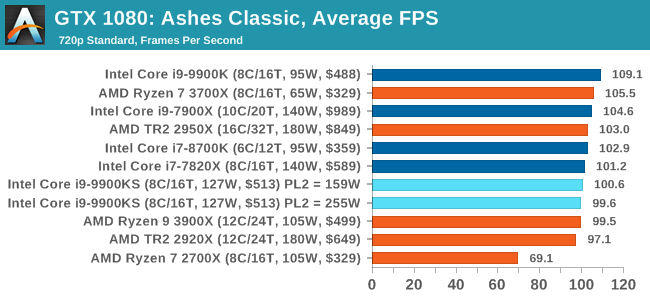
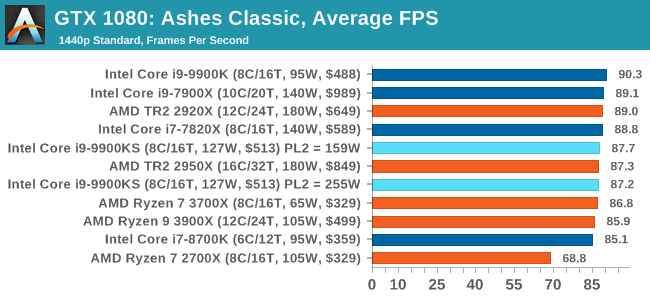

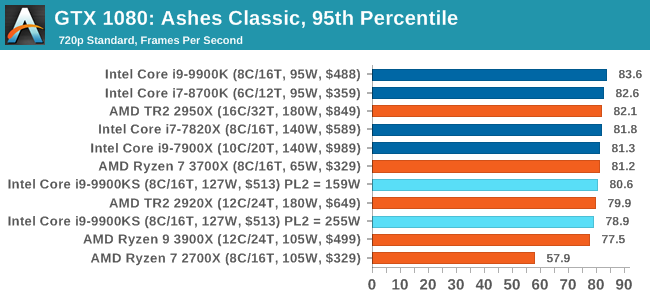
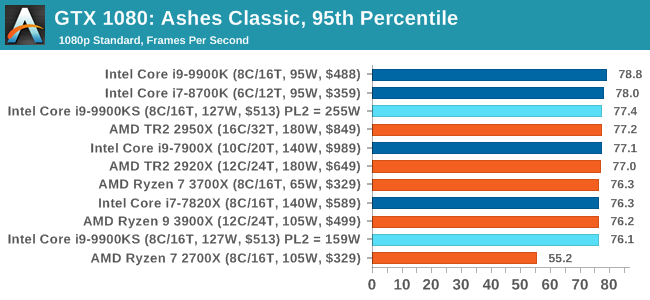
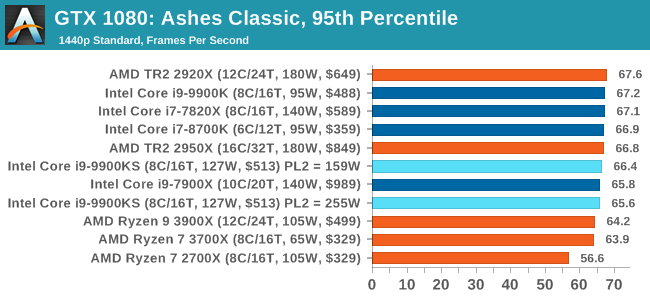
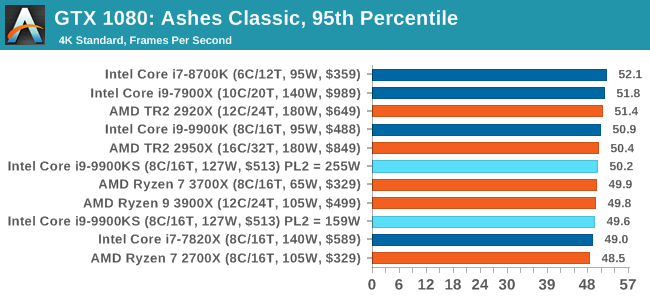

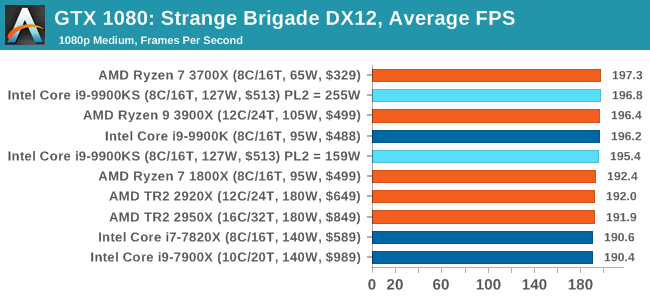
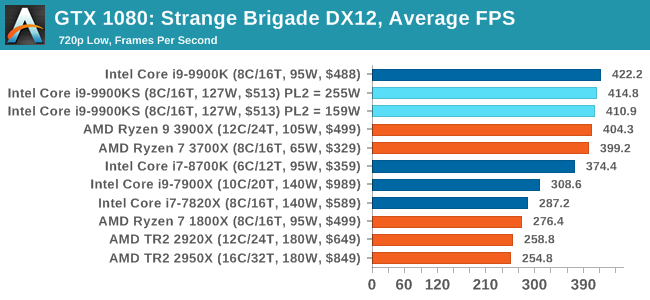
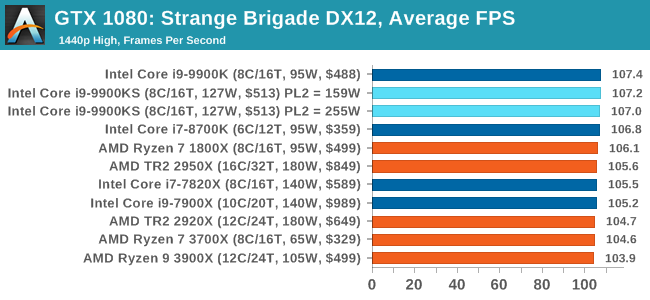
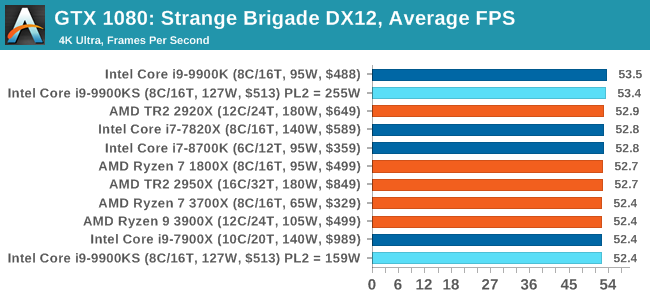
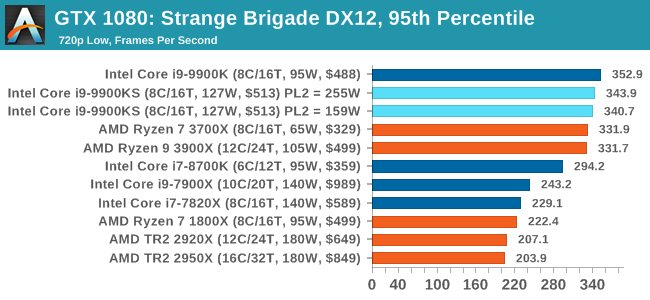
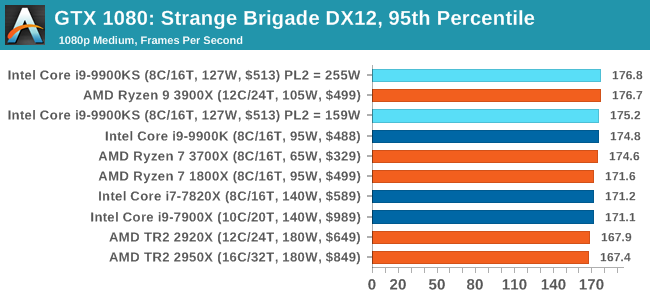
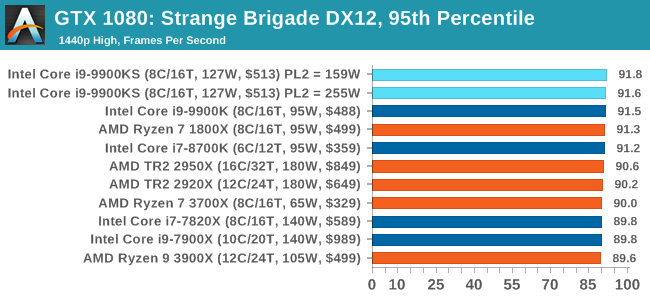
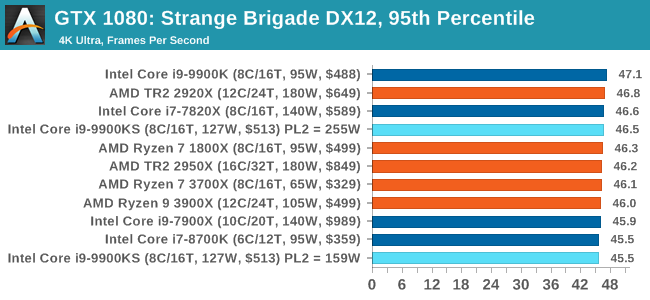
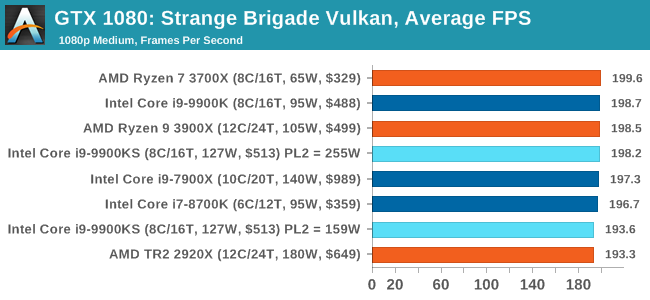
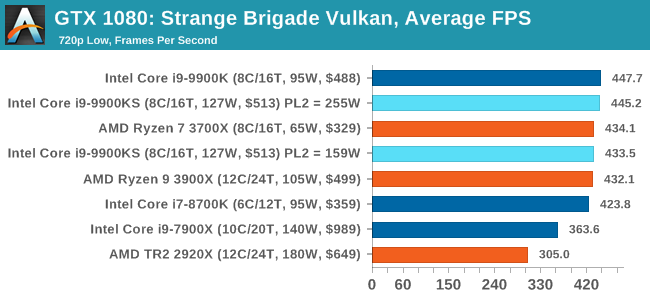
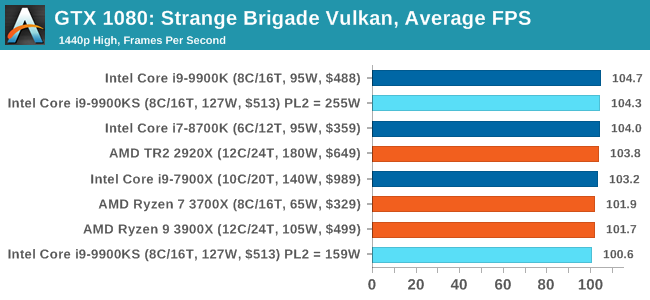
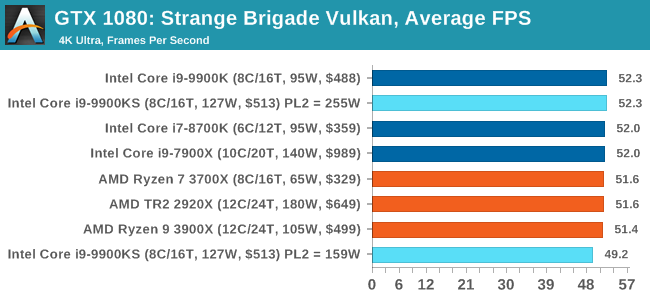
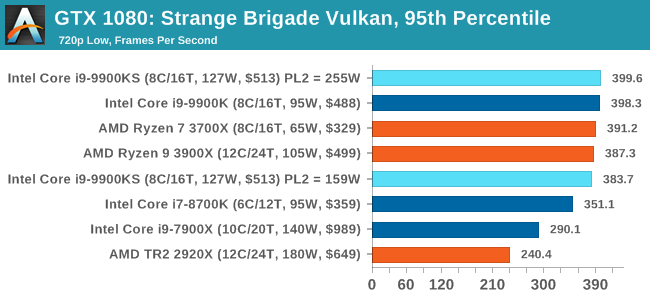
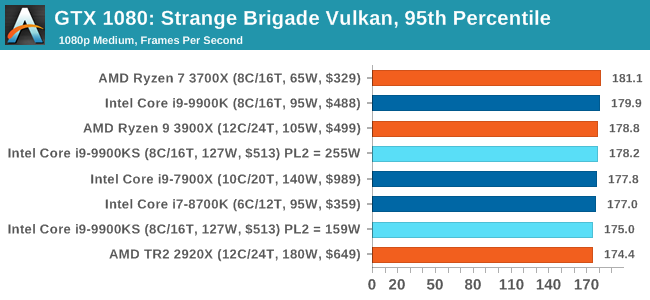
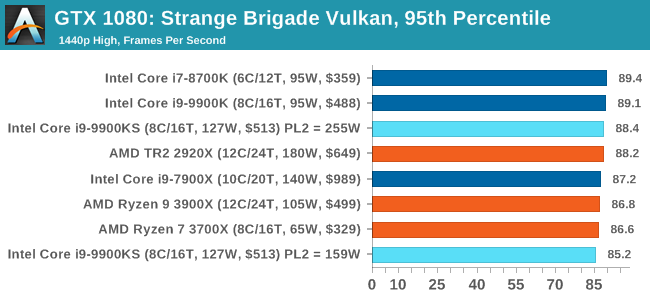
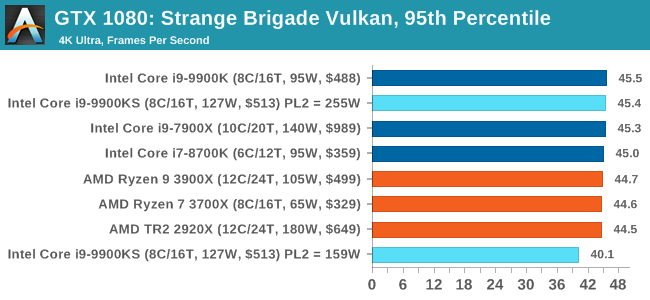

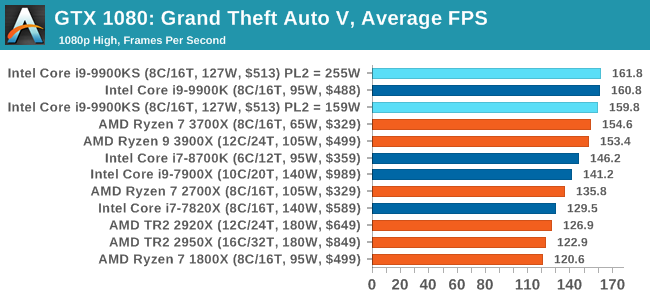
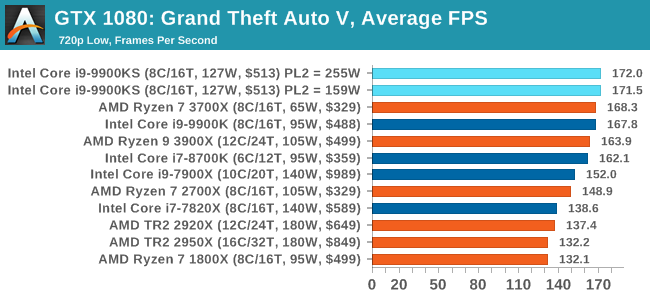
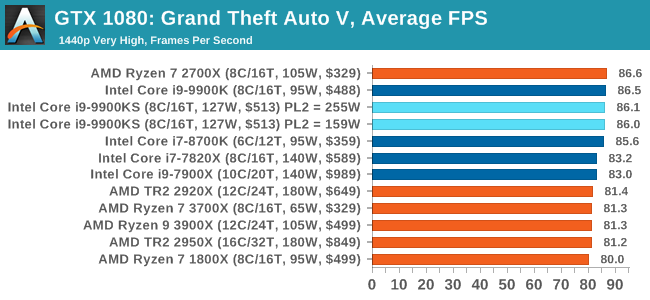
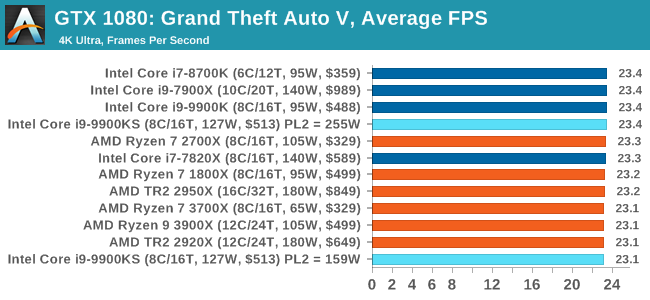
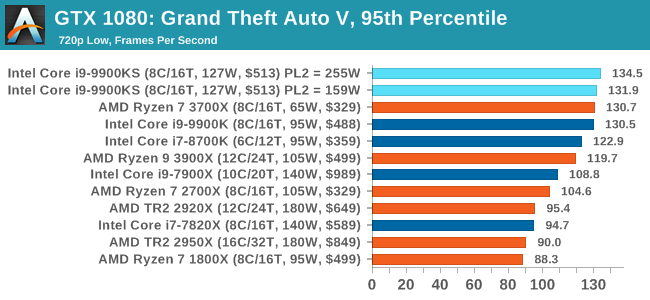
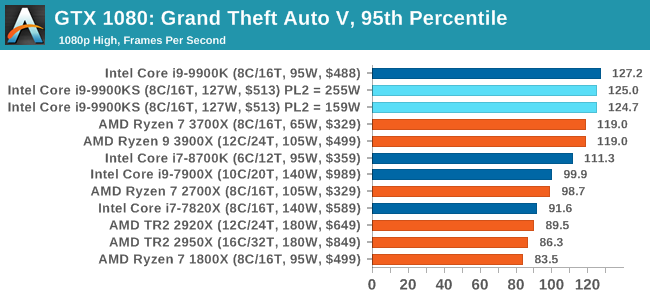
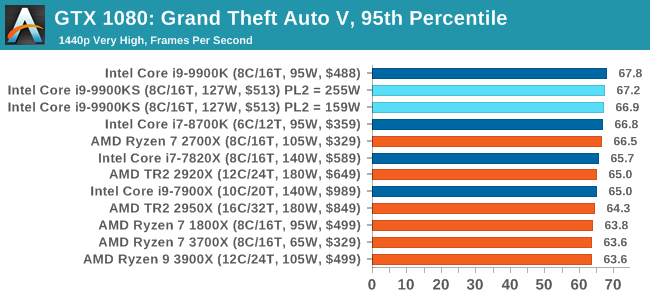
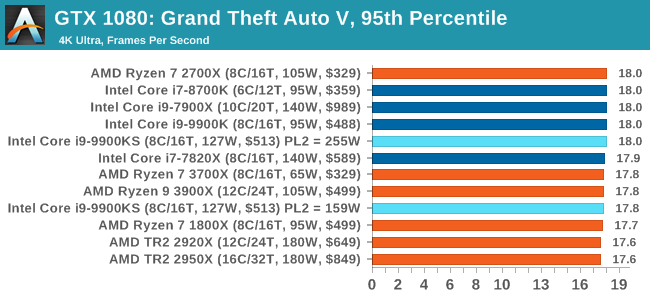

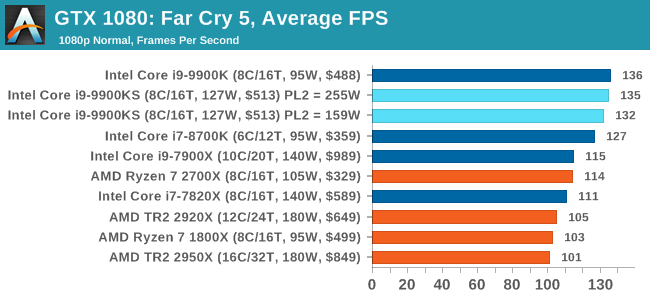
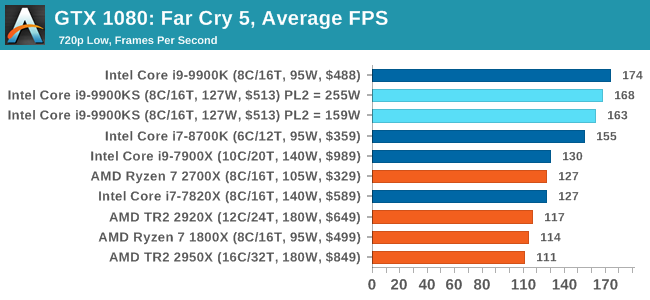
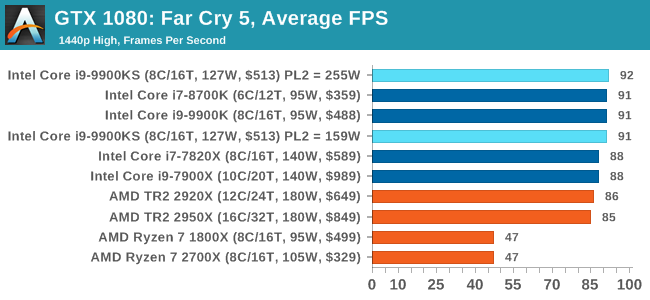
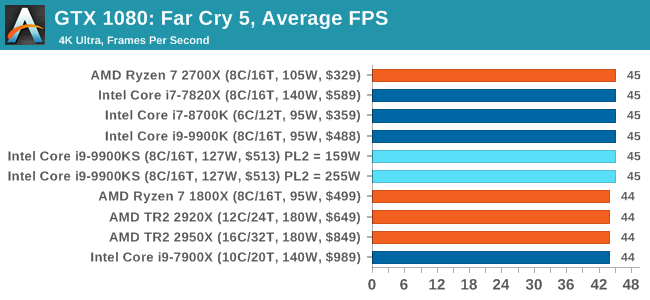
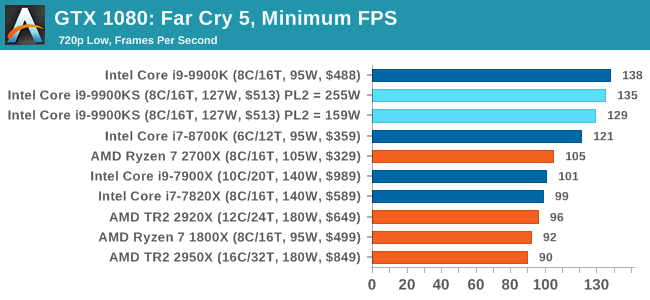
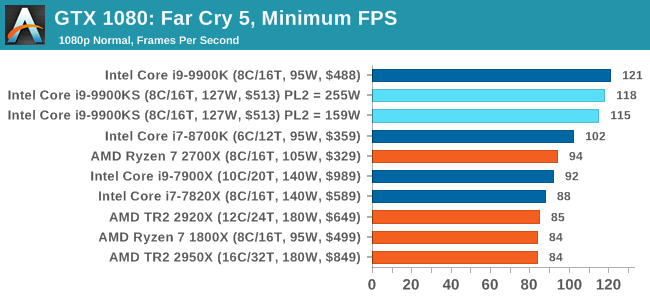


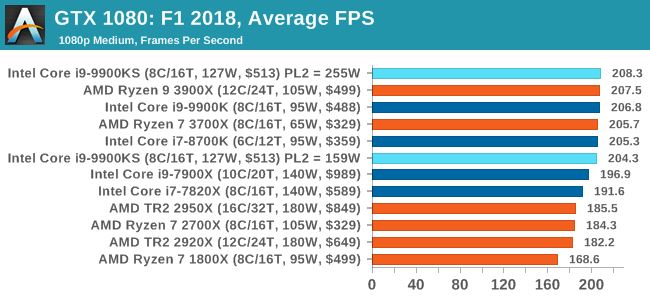
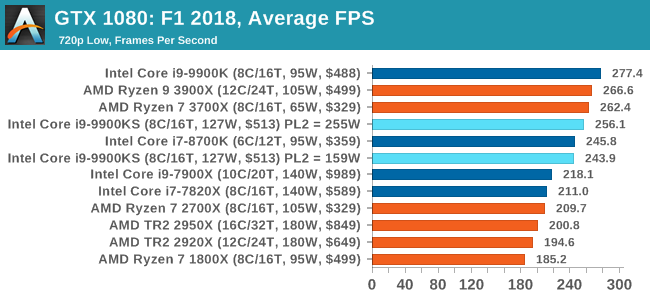
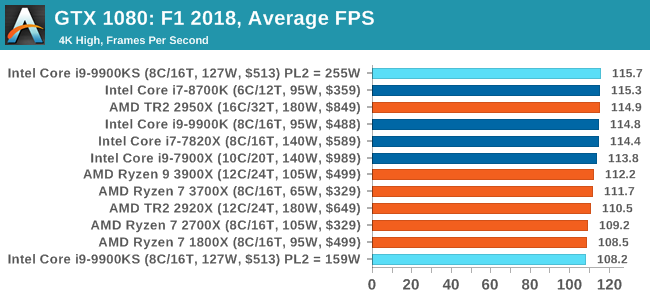
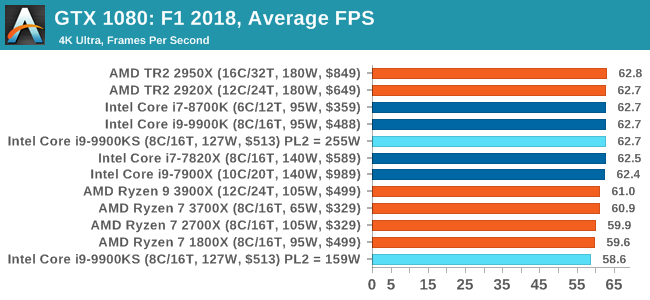
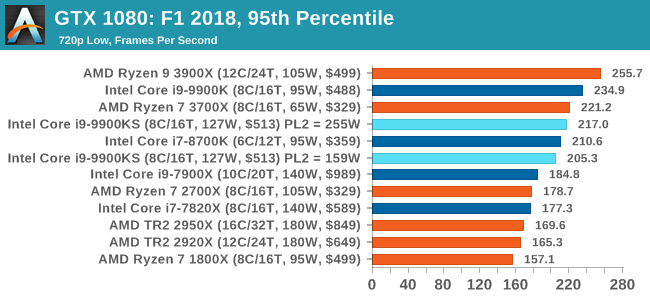
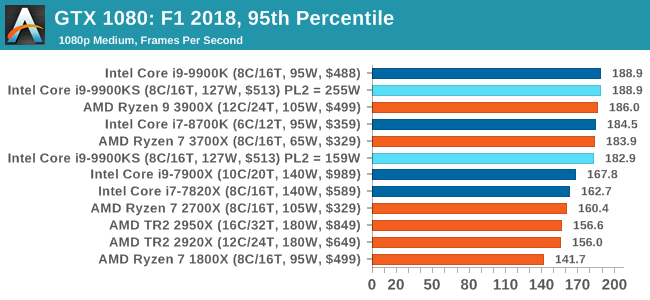
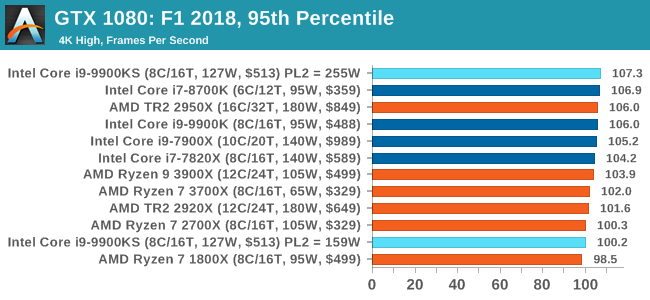
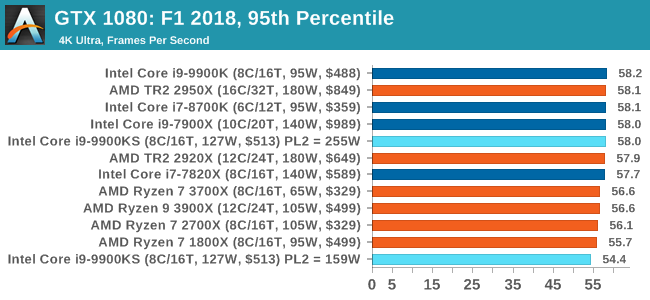





 RSS Feed
RSS Feed

{kind=link}